lustre与gpfs学习

1. 特点
- lustre分布式文件系统支持ldiskfs和zfs两种文件系统,ldiskfs是基于ext4文件系统定制优化而来(需要修改内核);zfs则是采用openzfs的项目。


2. lustre核心组件
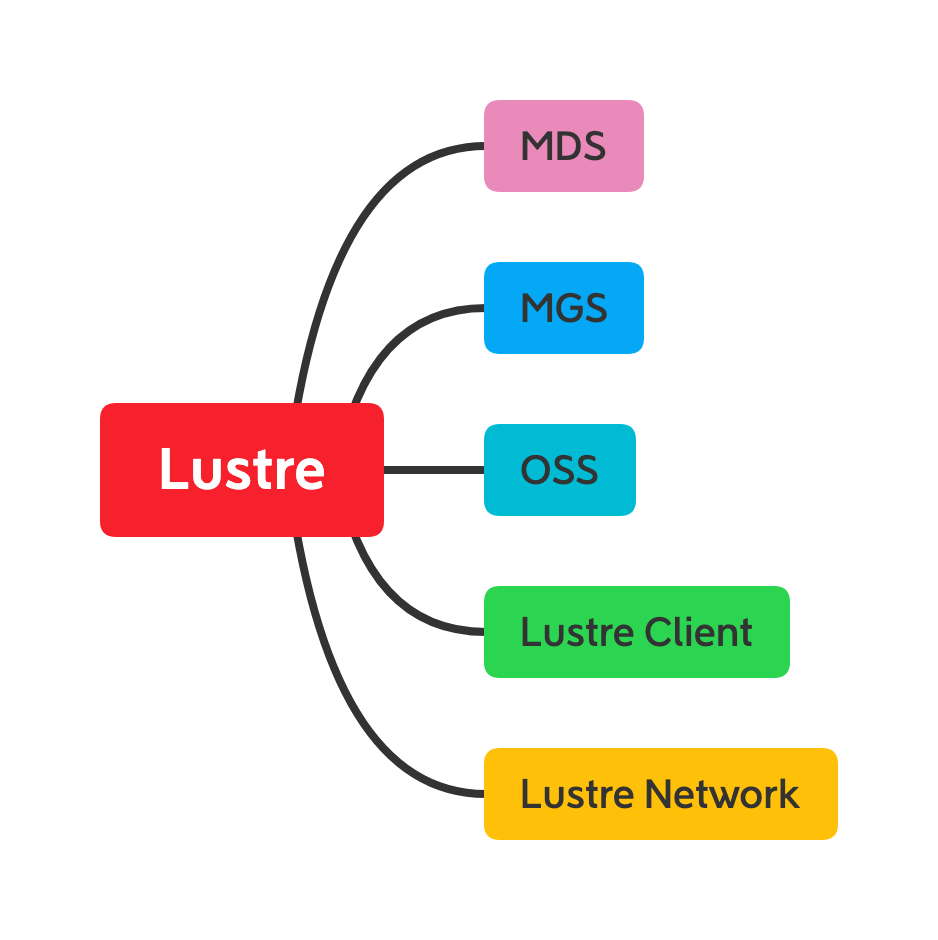
MGS(Management Server) :提供整个文件系统的配置信息与崩溃恢复
MGT(Management Target):MGT是MGS用于存储lustre文件系统配置信息的块设备,MGT的容量最大需要100MB。
MDS(Meta Server):MDS负责管理文件系统统一的命名空间,同时提供文件系统的元数据访问服务
MDT(Metadata Target):MDS存储元数据信息的后端块设备。
OSS(Object Storage Server):OSS负责管理文件对象数据,对lustre客户端提供完整文件数据的访问。
OST(Object Storage Target):OSS使用的存储文件对象数据的块设备。
LMV(Logical Metadata Voliume):访问
MDC(Metadata client)的抽象层LOV(Logical Object Volume):针对OSC(Object Storage Client)的抽象层Lustre Client:负责挂载lustre文件系统
Lustre Network:lustre的网络协议,支持RDMA
LIBCFS:提供基础的进程管理和调试 API。libcfs 被大量使用在 LNet、Lustre 的相关工具上。
3. 布局
- 正常(normal)文件布局
文件的每个stripe按照round-robin方式轮询当前集群中每个ost来放置数据分片对象。

- 复合布局

- 需要注意后面的部分会空出前面配置的空间大小
4. 访问流程
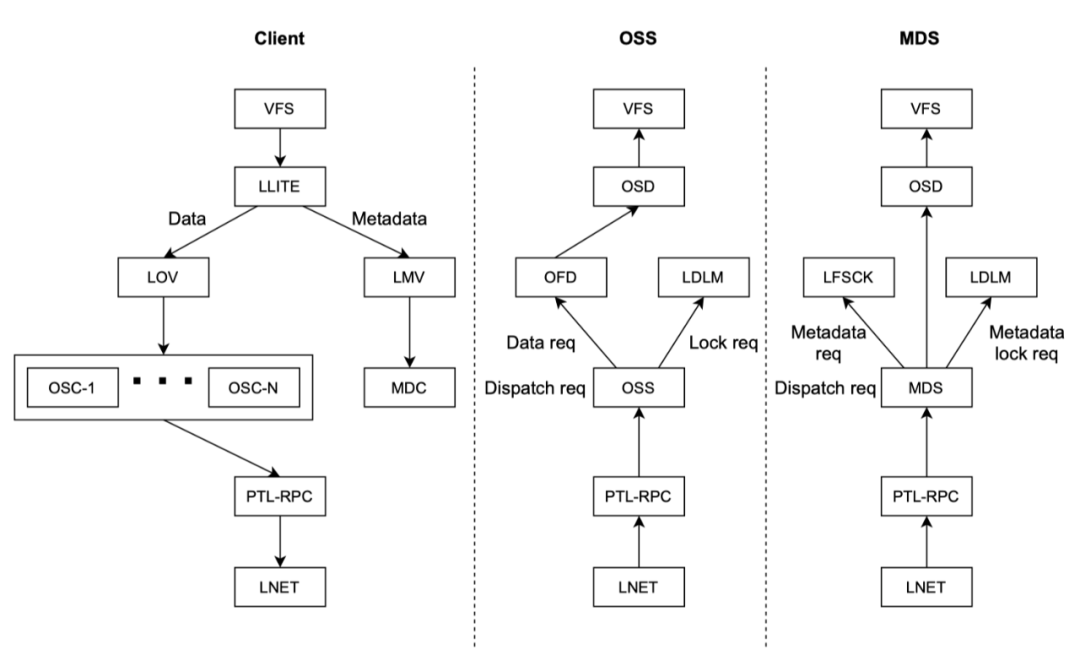
4. 代码分析
4.1 执行流
- lustre客户端stack中,一个文件处理需要
vvp_object、lov_object、lovsub_object、osc_object。每一层的对象都会包含通用的对象层cl_object.vvp_object是vfs-vm-posix层的对象,这个包含了操作文件的inode和cl_object的客户端通用对象;lov_object是为了处理来自vvp_object的封装的数据,其中也包含了cl_object,这一层是逻辑对象层,比如文件被stripe后,在lov_object会包含多个sripe的对象,这些对象封装成对象lovsub_object,每一个lovsub_object对应一个osc_object对象。最后osc_object通过自己这一层的device的接口层,数据到mds或者oss. - cio_submit和cio_commit的区别在于cio_submit用于紧急请求。
- wakeup all cache waiters->spin_unlock(&cli->cl_loi_list_lock);
(flock是文件锁)Mounting a Lustre File System on Client Nodes - Lustre Wiki
- read: ll_file_operations_flock->ll_file_read->(init_sync_kiocb)ll_file_aio_read->ll_file_read_iter->(do_loop_readv_writev)do_file_read_iter->pcc_file_read_iter/ll_do_fast_read/ll_file_io_generic->(vvp_env_new_io/cl_io_rw_init/range_lock_init)cl_io_loop->(cl_io_lock)cl_io_start->vvp_io_ops/lov_io_ops/mdc_io_ops/osc_io_ops(类型在do_file_read_iter赋值为CIT_READ=1,全局由cl_io_slice_add与lov_io_init_composite赋值为lov_io_ops)->lov_io_start->lov_io_call->cl_io_start(调用子请求)—–>osc_io_read_start
- submit:lov_io_submit->cl_io_submit_rw->cio_submit->osc_io_submit->osc_page_submit/osc_queue_sync_pages->(osc_extent_lookup/osc_extent_alloc)list_add_tail/osc_update_pending
- commit: lov_io_commit_async->cl_io_commit_async->cio_commit_async->osc_io_commit_async->osc_page_cache_add->osc_queue_async_io->osc_enter_cache->cli_unlock_and_unplug->osc_io_unplug_async->osc_io_unplug0->osc_check_rpcs/ptlrpcd_queue_work(异步)->(osc_send_write_rpc->osc_build_rpc->)ptlrpcd_add_req
- seek: ll_file_seek->cl_sync_file_range->cl_io_loop
5. GPFS
5.1 GPFS小文件并行
对于单个小文件的读写,GPFS(IBM Spectrum Scale)没有数据层面的并行策略(即不会像大文件那样将一个文件切分并通过多个磁盘并发读取)。
但是,GPFS 针对小文件有非常独特的优化策略,并且在处理海量小文件并发(Workload Parallelism)时具有极强的并行能力。
我们需要区分“单个小文件的并行”和“海量小文件吞吐的并行”:
1. 单个小文件:没有数据条带化并行 (No Striping)
在 GPFS 中,数据是以 Block(块) 为单位进行跨磁盘条带化(Striping)的。默认 Block Size 通常很大(如 4MB、8MB 甚至 16MB)。
如果文件 < Block Size(例如 100KB):
GPFS 不会将这 100KB 拆分存放到多个磁盘上。它会存储在单个磁盘的单个 Block 的部分 Sub-blocks(子块) 中。- 结果: 读写这个文件时,IO 只会落在一个 NSD(存储节点)的一块物理磁盘上,无法利用多磁盘并行加速。
2. GPFS 针对小文件的特殊优化策略
虽然没有并行,但 GPFS 有两项核心技术来极致优化小文件性能,目的是减少 IO 次数和节省空间:
A. Data-in-Inode (数据内嵌 Inode)
这是针对极小文件(通常 < 3.5KB)的最强优化。
原理: GPFS 的 Inode(文件元数据索引节点)大小通常默认为 4KB。如果你的文件非常小(例如 1KB 的配置文件或脚本),GPFS 会直接将文件内容存放在 Inode 结构体内。
优势:
零数据 IO: 读取文件属性(ls -l)时,文件内容就已经被读进内存了。读取文件内容不需要额外的磁盘 IO(Seek)。
极大提升性能: 相当于把元数据和数据合二为一,减少了一半的物理 IO 操作。
B. Sub-block (子块分配)
这是针对中等小文件(大于 4KB 但远小于 Block Size,如 100KB)的优化。
原理: GPFS 将一个大 Block(如 4MB)逻辑上划分为 32 个 Sub-blocks(子块)。
策略: 当文件写不满一个大 Block 时,GPFS 只分配必要的 Sub-blocks。
优势: 主要是为了节省空间(避免 1KB 文件占用 4MB 磁盘),同时通过聚合多个小文件的 Sub-blocks 到同一个物理 Block 中,可以在后续顺序读取时利用预读缓存。
3. 海量小文件:元数据并行 (Metadata Parallelism)
“并行策略”虽然在单个文件上不适用,但在并发读写成千上万个小文件时,GPFS 的并行威力就体现出来了。这主要归功于它的分布式元数据架构:
动态元数据节点 (Dynamic Metadata Management):
GPFS 没有像 HDFS 那样单一的 NameNode 瓶颈。目录和文件的元数据管理权是动态分布在所有节点上的。节点 A 创建文件 1,节点 B 创建文件 2,它们可以互不干扰地并行写入元数据。目录哈希 (Directory Hash):
对于同一个大目录下的海量小文件,GPFS 会对文件名进行 Hash,将它们分散存储在不同的元数据 Block 中。这意味着多个客户端可以同时在一个目录下创建文件,而不会因为锁竞争(Lock Contention)卡死。
关键结论
如果正在针对 GPFS 优化小文件应用:
不要指望单文件吞吐: 单个 1MB 文件的读写速度取决于单块磁盘的物理性能和网络延迟。
利用并发: 只有同时发起多个线程读写多个小文件,才能跑满 GPFS 的带宽。
调整 Inode 大小: 如果你的业务全是 1KB-3KB 的文件,确保存储池的 Inode Size 配置为 4KB(默认值),以启用 Data-in-Inode 功能。
5.2 GPFS调优
GPFS (IBM Spectrum Scale) 的优化是一个系统工程,核心理念是“用内存换 IO”和“匹配业务模型”。优化方案通常根据业务是“海量小文件(元数据密集型)”还是“大文件吞吐(带宽密集型)”而截然不同。
以下是针对不同场景的 GPFS 优化策略指南:
1. 核心参数调优 (通过 mmchconfig 修改)
这些参数可以在集群运行时动态调整(部分需要重启 GPFS 服务),是调优的第一战场。
| 参数名 | 推荐值/调整方向 | 适用场景 | 作用解释 |
|---|---|---|---|
pagepool |
物理内存的 20%-50% | 大文件/通用 | GPFS 的数据缓存。值越大,能缓存的数据越多,读写性能越好。这是最重要的性能参数。 |
maxMBpS |
2 * (网卡带宽 + 磁盘带宽) | 大文件吞吐 | 这不是限制速度,而是告诉 GPFS 你期望的吞吐量,GPFS 会据此计算预读(Prefetch)和后台写(Write-behind)所需的缓冲区大小。设得太小会限制吞吐。 |
maxFilesToCache |
10,000 ~ 100,000+ | 海量小文件 | 缓存在内存中的文件 inode 数量。小文件业务(如 AI 训练、代码编译)必须调大此值,避免反复读取磁盘元数据。 |
maxStatCache |
4 * maxFilesToCache | 海量小文件 | 缓存 stat() 结果(如 ls -l)。如果用户频繁列出目录属性,调大此值可大幅降低延迟。 |
worker1Threads |
默认值或适当增加 | 并发处理 | 处理常规文件操作的线程数。如果 mmdiag --threads 显示大量等待,可尝试增加。 |
prefetchThreads |
适当增加 (如 72-100) | 顺序读 | 专门用于数据预读的线程数。增加此值可提升大文件顺序读性能。 |
💡 操作提示:
修改参数命令:mmchconfig pagepool=16G -i (-i 表示立即生效且永久保存)。
2. 针对“海量小文件”的优化 (AI、Web、编译)
小文件性能瓶颈在于元数据(Metadata)处理,而非带宽。
开启
Data-in-Inode(关键):- 如果在
mmcrfs创建文件系统时指定-I(Inode Size) 为 4KB(推荐值),那么小于 ~3.5KB 的文件会直接存放在 Inode 中,无需分配额外的 Data Block,节省一次 IO。
- 如果在
元数据与数据分离:
- 使用高性能 SSD/NVMe 单独构建 System Pool (存放 Metadata),而用 HDD 存放 Data Pool。这能让
ls、find、stat操作飞快。
- 使用高性能 SSD/NVMe 单独构建 System Pool (存放 Metadata),而用 HDD 存放 Data Pool。这能让
调整 Block Size:
- 虽然默认 4MB/8MB 对大文件好,但如果全是小文件,过大的 Block 会导致锁竞争和空间浪费(虽然有 Sub-block 机制)。但通常不要为了小文件盲目调小 Block Size,更应依赖 SSD 元数据盘。
3. 针对“大文件高吞吐”的优化 (视频编辑、HPC、备份)
大文件性能瓶颈在于网络带宽和磁盘吞吐。
Block Size 对齐 (必须):
GPFS 的 Block Size 最好与底层 RAID 条带大小(RAID Stripe Size)对齐。
例如:RAID 6 (8+2),条带深度 256KB,则全条带写大小为 8 * 256KB = 2MB。GPFS Block Size 应设为 2MB、4MB 或 8MB。
网络巨型帧 (Jumbo Frames):
- 确保交换机和服务器网卡均开启 MTU 9000。这对提升吞吐量至关重要。
RDMA (RoCE/InfiniBand):
- 如果硬件支持,务必开启 GPFS 的 RDMA 功能。它能绕过 CPU 直接传输数据,大幅降低延迟并提升带宽。
4. 客户端(Client) vs 服务端(NSD Server) 差异
不要在所有节点上应用相同的配置。
NSD Server (存储节点):
重点: 甚至可以牺牲
pagepool(如果内存紧缺) 来保证底层 IO 调度的内存。参数: 关注
nsdMaxWorkerThreads,确保能处理来自成百上千个 Client 的请求。
Client (计算节点):
- 重点: 尽可能大的
pagepool和maxFilesToCache。因为数据是在 Client 端缓存的,Client 内存越大,应用感觉越快。
- 重点: 尽可能大的
5. 诊断与排查工具
优化不是盲目的,先用工具看瓶颈在哪里。
查看当前性能:
mmpmon
Bash# 进入交互模式查看 IOPS 和吞吐 mmpmon -i > io_s查看等待原因:
mmdiag --waiters- 这是排查 GPFS 卡顿的神器。如果看到大量
Network等待,查网络;如果看到Disk等待,查底层存储。
- 这是排查 GPFS 卡顿的神器。如果看到大量
总结优化清单
| 优化动作 | 优先级 | 收益 |
|---|---|---|
调大 pagepool |
⭐⭐⭐⭐⭐ | 通用性能提升最大 |
| SSD 存放 Metadata | ⭐⭐⭐⭐⭐ | 小文件性能质变 |
| 开启 RDMA / Jumbo Frames | ⭐⭐⭐⭐ | 大带宽场景必备 |
调大 maxFilesToCache |
⭐⭐⭐⭐ | 解决小文件“卡顿”感 |
| Block Size 对齐 RAID | ⭐⭐⭐ | 写入性能稳定性提升 |
5.3 小文件优化方向
如果对 GPFS 的小文件并行做了“特殊优化”,通常并没有修改 GPFS 的内核源码(因为那是 IBM 的闭源核心)。
他们所谓的“优化”,通常是在架构设计、中间件层或配置策略上做了手脚。以下是最可能采用的几种技术手段,由浅入深解析:
1. 中间件层:IO 聚合(最有效的“假”并行)
这是解决小文件问题的终极方案。既然 GPFS 不喜欢小文件,那就不要给它小文件。
原理: 开发一个中间件库(Library)或使用特定格式(如 HDF5, ADIOS),在客户端内存中拦截小文件的写入请求。
做法:
Buffer: 将成百上千个 1KB 的小文件在内存中缓存起来。
Aggregation: 拼凑成一个 4MB 或更大的“大块数据”。
Flush: 一次性通过并行 IO 写入 GPFS。
宣称口径: “我们实现了小文件的高速并行写入。”(实际上是把小文件变成了大文件写)。
2. 缓存层:引入 Burst Buffer 或 NVMe Tier
利用速度极快的介质作为“缓冲区”,掩盖底层机械硬盘处理小文件的延迟。
HAWC (High Availability Write Cache):
做法: 在所有 NSD 服务器上配置非易失性内存(NVDIMM)或极速 NVMe SSD 作为 GPFS 的 Log/Journal 区。
效果: 小文件的创建和写入只需写入到这个高速缓存并同步元数据,立刻返回“成功”给客户端。后台再慢慢刷到慢速硬盘。
LROC (Local Read-Only Cache):
做法: 在计算节点(Client)的本地 SSD 上开启 LROC。
效果: 读过的小文件缓存在本地 SSD。下次读取时直接走本地 IO,不走网络,不经过 GPFS Server,看起来并发读取能力“无限大”。
3. 数据分布策略:FPO (File Placement Optimizer)
如果是在做大数据或 Hadoop 迁移场景,可能使用了 GPFS 的 FPO 功能。
原理: 类似 HDFS 的“数据本地化”。
做法: 让小文件的数据块(Block)强制存放在发起写入的那台机器的本地磁盘上,而不是跨网络去存。
效果: * 写入时:本地落盘,没有网络开销。
读取时:计算任务调度到数据所在的节点,本地读取。
宣称口径: “实现了计算与数据的完美并行,消除了网络瓶颈。”
4. 元数据(Metadata)架构的极致拆分
对于小文件,瓶颈往往在 create, lookup, stat 操作上。
独立且巨大的 Metadata Pool:
做法: 强制要求 Metadata 必须存放在 Optane (傲腾) 或高端 NVMe 阵列上。
参数调优: 将
inode-size设为 4KB(启用 Data-in-Inode),并且预先分配极其巨大的 Inode 空间,避免动态扩展带来的性能抖动。
多活元数据服务器 (Multiple Metadata Servers):
- 通过调整
metanodes参数,允许集群中更多的节点参与元数据管理,分摊ls -R或海量创建时的压力。
- 通过调整
5. 目录哈希与预分配 (应用层规约)
这属于“软优化”,通常是指导用户修改代码。
目录打散 (Directory Sharding):
如果公司声称优化了并行,可能是他们强制实施了目录分层规范。GPFS 如果在一个目录下存放百万级文件,性能会骤降。
策略: 强制将文件 Hash 到
/data/a/b/c/这样的多级目录结构中,利用 GPFS 的目录 Hash 锁机制,让不同的 Metadata Node 并行处理不同的子目录。
6. 网络协议优化:RDMA / RoCE
这不针对小文件,但对小文件收益巨大。
做法: 全链路开启 RDMA(InfiniBand 或 RoCE v2)。
原因: 小文件的特点是“交互多、数据少”。TCP/IP 协议栈的 CPU 中断开销在小文件场景下占比极高。RDMA 绕过 CPU,能显著降低小文件传输的时延(Latency)。
如何验证他们的“优化”含金量?
可以问以下 3 个问题来通过“照妖镜”查看真相:
“你们是优化了单个小文件的 Striping,还是优化了 Throughput?”
- 如果是前者,大概率是忽悠(除非改源码)。如果是后者,属于正常调优。
“是否使用了 Data-in-Inode?如果文件大小稍微超过 4KB 性能会怎样?”
- 这能看出他们是否单纯依赖 GPFS 的内嵌数据特性。如果超过 4KB 性能断崖式下跌,说明除此之外没招了。
“是否有客户端侧的聚合(Aggregation)中间件?”
- 如果有,这意味着你的应用程序可能需要修改代码(调用他们的 API),或者需要接受非标准的挂载方式。
总结: 真正的优化通常是 “全闪存元数据盘” + “Data-in-Inode” + “大内存缓存(Pagepool)” + “RDMA 网络” 的组合拳。所谓的“黑科技”通常只是应用层的聚合(Aggregation)。
5.4 兼容层
GPFS 的 GPL 开源兼容层(GPL Portability Layer) 中非常接近核心的部分,专门用于处理 GPFS 与 Linux 内核 NFS 服务 (CNFS/KNFS) 的交互。
我们可以通过代码里的几个“行话”来确凿地鉴定它:
1. 铁证:“Data Shipping” (数据搬运)
请看代码中这句极其关键的注释:
/* We cannot use pNFS if data shipping is used ... */
什么是 Data Shipping? 这是 GPFS (Spectrum Scale) 架构中特有的术语。
Direct Access: 节点直接读写物理磁盘(快)。
Data Shipping: 节点无法直接访问磁盘,必须请求另一个节点把数据通过网络“搬运”过来(慢)。
证据力: 绝大多数通用文件系统(ext4, xfs)或者其他分布式系统(Ceph, Gluster)都不使用 “Data Shipping” 这个特定的术语来描述这种机制。这是 GPFS 的“方言”。
2. 铁证:“sx byte range locks” (共享/排他字节范围锁)
注释后半部分:
... since DS also uses sx byte range locks.
GPFS 的核心强项就是其复杂的分布式锁管理器 (Token Manager)。
SX Lock (Shared/Exclusive Lock) 是 GPFS 内部管理并发写入一致性的核心机制。这段代码在解释为什么要在特定情况下禁用 pNFS —— 因为“数据搬运”机制和“pNFS 并行访问”在锁的机制上会打架。
3. 代码逻辑分析:它在做什么?
这段代码正在做 “能力协商”。
场景: 这是一个 Linux 节点,挂载了 GPFS,并且试图通过 NFS 协议把这个 GPFS 目录共享出去(Export)。
判断: 代码正在检查
vinfoP(vnode info pointer,文件节点信息)。冲突检测:
如果当前处于 Data Shipping 模式(意味着本机访问磁盘很慢,或者没有直连磁盘),
并且试图开启 pNFS (Parallel NFS,一种让客户端并行直连存储的高级 NFS 功能)。
决定: 此时代码说“不行” (
pNFS = false)。- 原因: 如果你本机都还要靠别人搬运数据,就别对外宣称支持 pNFS 并行直连了,而且锁机制会冲突。
4. 结论:这段代码属于哪?
这段代码通常位于 GPFS 安装包中的 /usr/lpp/mmfs/src/ 目录下。
它是 GPFS 的源码吗? 是的,它是 IBM 编写并分发给你的 GPFS 源代码。
它是闭源核心吗? 不是。
它是 GPL Portability Layer (GPL 兼容层) 的一部分。
为什么你能看到它? 因为这段代码必须和 Linux 内核(GPL协议)进行链接。为了不违反 Linux 的开源协议,IBM 被迫 将这部分“胶水代码”开源。
它的作用: 它是连接 Linux 内核标准 NFS 服务 (
knfsd) 和 GPFS 闭源核心 (mmfs模块) 的桥梁。
5. 位置
这个“兼容层”(GPL Portability Layer)的源码并不在神秘的地方,它就静静地躺在你安装了 GPFS(IBM Spectrum Scale)的每一台 Linux 机器上。
只要你安装了 GPFS 的基本包,源码通常位于以下标准路径:
1. 核心路径 (The Holy Grail)
所有对外公开的“胶水代码”都集中在这里:
Bash
/usr/lpp/mmfs/src/
2. 具体目录结构解析
进入这个目录后,你会看到几个关键的子目录,它们对应不同的功能:
/usr/lpp/mmfs/src/gpl-linux/这是你最关心的部分。
这里存放了 GPFS 对接 Linux 内核 VFS(虚拟文件系统)的所有代码。
关键文件: 你会在里面找到类似
kdump.c,mmfs_linux.c等文件。这些代码定义了 Linux 内核如何调用 GPFS(比如inode_operations,file_operations结构体的映射)。
/usr/lpp/mmfs/src/config/这里存放的是编译脚本(Makefiles)和环境检测脚本。
当你运行
mmbuildgpl命令编译内核模块时,就是这里面的脚本在工作。
/usr/lpp/mmfs/include/(虽然不在 src 下,但紧密相关)这里存放了头文件(Header Files),例如
gpfs.h。如果你想写一个 C 程序来调用 GPFS 的 API(比如前面看到的
gpfs_ganesha接口),就需要引用这里的头文件。
3. 关于你之前截图的代码 (NFS-Ganesha)
注意: 你上一张截图里的代码(涉及 FSAL 和 gpfs_ganesha 调用)通常不包含在 /usr/lpp/mmfs/src 里。
那部分代码属于 NFS-Ganesha 开源项目。它的位置取决于你是怎么安装 NFS-Ganesha 的:
如果是从 GitHub 下载源码编译:
路径通常在:
nfs-ganesha/src/FSAL/FSAL_GPFS/你可以直接访问 GitHub 查看:GitHub - nfs-ganesha/nfs-ganesha: NFS-Ganesha is an NFSv3,v4,v4.1 fileserver that runs in user mode on most UNIX/Linux systems
如果是通过 IBM 安装包安装的 Ganesha:
- IBM 通常只提供编译好的二进制文件 (
rpm或deb),源码可能不会直接释放到你的磁盘上。你需要去下载对应的.src.rpm包解压才能看到源码。
- IBM 通常只提供编译好的二进制文件 (
总结
如果你想看 GPFS 如何对接 Linux 内核:去
/usr/lpp/mmfs/src/gpl-linux/。如果你想看 NFS 如何对接 GPFS(你截图的部分):去 GitHub 搜
nfs-ganesha项目下的FSAL_GPFS目录。
你可以现在去你的机器上运行 ls -F /usr/lpp/mmfs/src/ 看看是否有这些文件。
参考
深入理解Lustre分布式文件系统之Lustre架构 - 墨天轮
HPC高性能计算知识:深度解析Lustre体系结构 - 腾讯云开发者社区-腾讯云
Mounting a Lustre File System on Client Nodes - Lustre Wiki
深入理解Lustre文件系统-第3篇 lustre lite - myjava2 - 博客园
深入理解 Lustre 系列一:Lustre 架构 - 知乎
深入理解Lustre文件系统-第4篇 LOV和OSC_深入理解 lustre-CSDN博客
linux内核读写IO过程中的iovec及其相关的结构体-CSDN博客
深入理解Lustre文件系统-第3篇 lustre lite - myjava2 - 博客园
IBM/ibm-spectrum-scale-install-infra: Spectrum Scale Installation and Configuration
深入探索GPFS在GitHub上的应用与实现 - github中文站
Building the GPFS portability layer on Linux nodes - IBM Documentation
- Title: lustre与gpfs学习
- Author: Ethereal
- Created at: 2024-12-02 00:12:48
- Updated at: 2025-12-08 21:03:57
- Link: https://ethereal-o.github.io/2024/12/02/lustre与gpfs学习/
- License: This work is licensed under CC BY-NC-SA 4.0.