llm learning

1. LoRA
主要参考
1.1 安装必要包
1 | pip install torch torchvision transformers diffusers peft Pillow tqdm pyyaml accelerate |
1.2 设置huggingface镜像
1 | export HF_ENDPOINT=https://hf-mirror.com |
1 | import os |
1.3 代码梳理
1.3.1 加载模型
加载噪声调度器:
noise_scheduler = DDPMScheduler.from_pretrained加载 Tokenizer:
tokenizer = CLIPTokenizer.from_pretrained加载 CLIP 文本编码器:
text_encoder = CLIPTextModel.from_pretrained加载 VAE 模型:
vae = AutoencoderKL.from_pretrained加载 UNet 模型:
unet = UNet2DConditionModel.from_pretrained转换为LoRA模型:
get_peft_model(text_encoder, lora_config)或PeftModel.from_pretrained(text_encoder, ...)获取可训练LoRA参数:
text_encoder.print_trainable_parameters()冻结不需要训练模型的参数:
vae.requires_grad_(False)
1.3.2 准备数据
自己定义数据类:
Text2ImageDataset(定义__init__、__getitem__、__len__方法)设定数据集预处理方法:
transforms.Compose加载数据集加载方法:
torch.utils.data.DataLoader与collate_fn
1.3.3 准备学习器
prepare_optimizer使用AdamW学习器
1.3.4 准备学习率调节器
get_scheduler
1.3.5 切入训练模式
1 | unet.train() |
1.3.6 计算损失
1 | # 获取原图像向量 |
1.3.7 反向传播
1 | loss.backward() |
其中,loss给可以调整的参数加上loss标记,做反向传播;optimizer根据学习率与计算方式将梯度应用到当前的参数上;lr_scheduler更新学习率
1.3.8 推理
切换为评估模式:
text_encoder.eval()创建SD执行流:
DiffusionPipeline.from_pretrained加载文本:
load_validation_prompts创建初始图像:采用随机数
torch.Generator推理
2. Beam Search
产生预测的方式:全部搜索(不可能)、贪心(不一定全局最优)、多路(束搜索)
3. 采样
top-k:排序后直接取前k个
top-p:排序后取大于p的
4. DPO微调
可以同时对正向和反向的文本进行编码,并根据两者计算loss
5. 量化
对称量化
非对称量化
区别在于量化值区间是否限制了量化前后零点对应
6. token与embedding
token:用于将文本映射成序列号
embedding:用于丰富token含义
7. Transformer
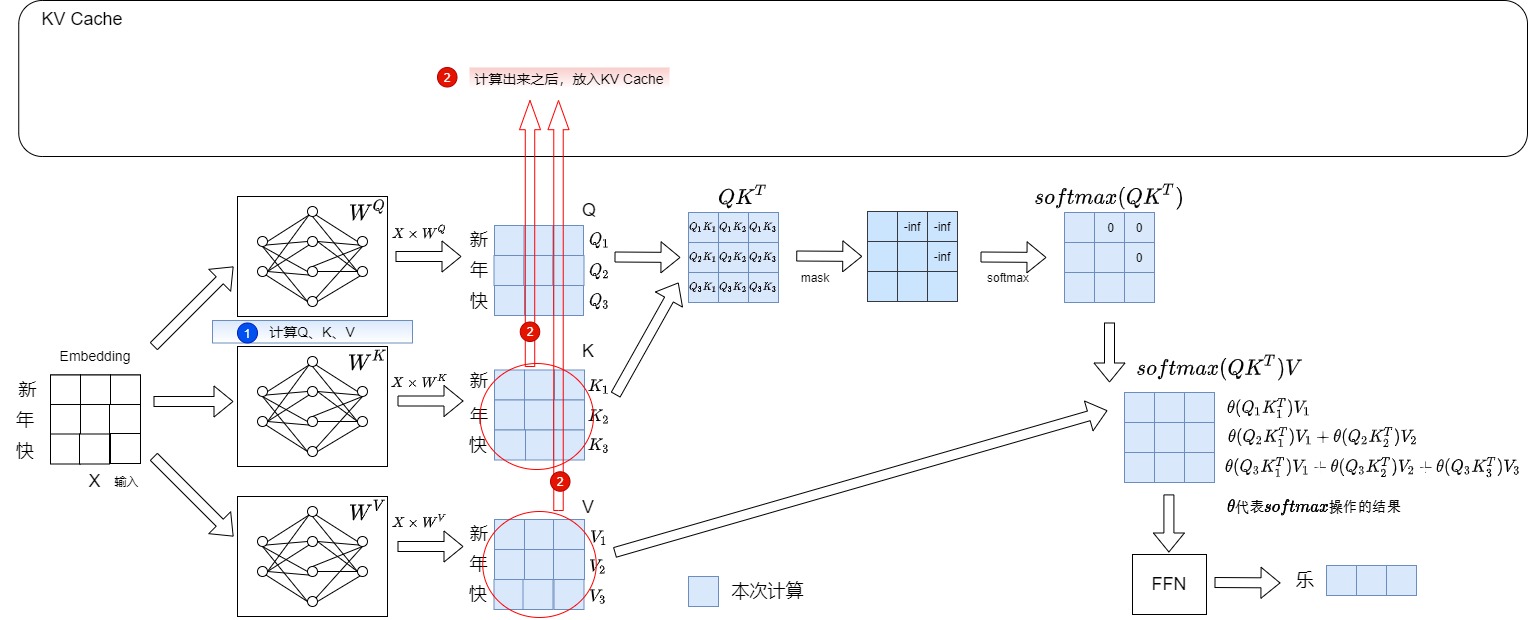
Mask: KV Cache因为mask才可以进行。因为mask的缘故,使得计算只需要求和前面的即可。
多级:更多层次地提取特征,相关性只是第一层通过注意力机制提取的特征。每级最终会经过FFN进一步归纳提取特征。
为什么多级不会损失位置信息?提前在embedding时候将位置信息拼接到后面了
RoPE:旋转位置编码,引入的位置信息包含更多的相对位置信息
计算权重:最终的经过FFN后的特征,再通过简单的线性层即可映射到词表空间,每个元素都是概率。通过搜索即可得到最大概率对应的词 。
多头注意力:将输入经过embedding之后的切成多份。
交叉注意力:Q与KV来自不同的样本,此时类似transformer经典的encode-decode架构
Multi-Head Latent Attention (MLA):通过低秩联合压缩技术,减少 K 和 V 矩阵的存储和计算开销
对 K 和 V 矩阵进行低秩联合压缩
对查询矩阵 Q 进行低秩压缩
修改注意力计算方式
CacheBlend
目标
- 提前缓存KV Cache
困难
KV Cache中携带位置信息
交叉注意力
解决方案
使用RoPE,将绝对的位置信息改为通过矩阵旋转即可得到的位置信息
观察到交叉注意力比较稀疏,因此只选取一些计算

8. 存储结合
8.1 LMCache
可以直接从源码安装
1 | pip install -e . |
例子都要求有GPU
8.2 llmperf
直接通过源码安装
1 | pip install -e . |
测试llm,可以指定地址
1 | export HF_ENDPOINT="https://hf-mirror.com" |
测试结果:
1 | \Results for token benchmark for gpt-4o queried with the openai api. |
8.3 部署配置要求
8.3.1 vllm
算力大于7,从这里查看:CUDA GPU Compute Capability | NVIDIA Developer
小于7可以魔改:Support for compute capability <7.0 · Issue #963 · vllm-project/vllm
部分算子需要大于8
8.3.2 lmcache
Cuda 10.0 或更高版本
先从这里获取显卡与驱动版本的对应:NVIDIA GeForce 驱动程序 - N 卡驱动 | NVIDIA
然后从这里获取驱动版本与CUDA对应:1. CUDA 12.9 Release Notes — Release Notes 12.9 documentation
9. 超长文本
9.1 位置编码
【位置编码速通】从ROPE到Yarn:通用公式解析长文本大模型的位置编码!_知识图谱_拥抱AGI-MCP技术社区
RoPE
Position Interpolation (PI):均匀拉伸的位置插值,也叫线性内插
NTK-Aware Interpolation:非均匀频率缩放,介于直接外推和线性内插之间的平滑方法
Dynamic Scaling:动态适配插值比例, NTK-Aware Interpolation升级版
NTK-by-parts Interpolation:基于波长局部分段插值
Yarn
9.2 分割
LLM - 长文本总结处理方案_当文档的长度过长时,llm怎样处理-CSDN博客
Map Reduce
Refine
Map Rerank
Binary Map
9.3 RAG
LLM大模型对超长文本处理的技术方案汇总(NBCE、Unlimiformer)_超长文档+大模型-CSDN博客
InfLLM:每次生成下一个token的时,Initial token和一个窗口内的token,Evicted token会分块,检索一部分token出来。(选取块中最具有特征的几个token)
猜测:选取的token可以事先计算?具有特征是否可以使用当下注意力最高的token
是否可以与位置编码融合?也就是说选取的token采用RoPE等方式计算:可能用处不大
NBCE:对长文本进行分段,对每段上文进行独立编码,在输出层对每一个Step预测token的概率矩阵进行融合
- 猜测:可能损失块之间的位置信息
PCW:基本同NBCE
MemLong:类似RAG,只给大模型传递索引
Unlimiformer:将注意力计算外包给一个k-最近邻(kNN)索引来实现
AutoCompress:长文本上下文压缩成紧凑的摘要向量,这些向量随后可以作为软提示(soft prompts)供模型使用。
10. 算子
算子是Pytorch等框架与底层如cuda或openvino交互的方式
10.1 添加C++实现
1 | at::Tensor mymuladd_cpu(at::Tensor a, const at::Tensor& b, double c) { |
以下是softmax实现:
1 | torch::Tensor softmax_impl(torch::Tensor input, int64_t dim) { |
10.2 注册算子
声明
1 | TORCH_LIBRARY(extension_cpp, m) { |
定义
1 | TORCH_LIBRARY_IMPL(extension_cpp, CPU, m) { |
为算子添加 torch.compile 支持
1 | # Important: the C++ custom operator definitions should be loaded first |
此外,也可以使用pybind方式注册算子。
10.3 添加训练支持
1 | def _backward(ctx, grad): |
参考
用 LoRA 微调 Stable Diffusion:拆开炼丹炉,动手实现你的第一次 AI 绘画_lora微调stable diffusion-CSDN博客
使用 Lora进行微调DeepSeek大模型_deepseek lora-CSDN博客
tloen/alpaca-lora: Instruct-tune LLaMA on consumer hardware
大模型轻量级微调(LoRA):训练速度、显存占用分析 - 知乎
Stable Diffusion(SD)核心基础知识——(文生图、图生图)_sd模型-CSDN博客
如何快速下载huggingface模型——全方法总结 - 知乎
huggingface-cli下载数据(含国内镜像源方法)_huggingface-cli download-CSDN博客
理解Pytorch的loss.backward()和optimizer.step() - 知乎
ComfyUI:Stable Diffusion 及 LoRA、VAE 、ControlNet模型解析 - 知乎
AIGC-Stable Diffusion之VAE - 知乎
探秘Transformer系列之(20)— KV Cache - 罗西的思考 - 博客园
LLM 推理加速 - KV Cache - MartinLwx’s Blog
注意力机制到底在做什么,Q/K/V怎么来的?一文读懂Attention注意力机制
拆 Transformer 系列二:Multi- Head Attention 机制详解 - 知乎
神经网络算法 - 一文搞懂 Softmax 函数-CSDN博客
翻译: 详细图解Transformer多头自注意力机制 Attention Is All You Need-CSDN博客
(80 条消息) 为什么加速LLM推断有KV Cache而没有Q Cache? - 知乎
注意力机制到底在做什么,Q/K/V怎么来的?一文读懂Attention注意力机制
(80 条消息) Transformer中的Attention机制,注意力分布概率是如何求得的? - 知乎
Multi-Head Latent Attention (MLA) 详细介绍(来自Deepseek V3的回答) - 知乎
举个例子讲下transformer的输入输出细节及其他 - 知乎
详解 CacheBlend:RAG 场景 KV 复用,打破前缀相同的限制 - 知乎
ray-project/llmperf: LLMPerf is a library for validating and benchmarking LLMs
【踩坑】pip安装依赖卡在Installing build dependencies …-CSDN博客
Example: Offload KV cache to CPU | LMCache
Support for compute capability <7.0 · Issue #963 · vllm-project/vllm
1. CUDA 12.9 Release Notes — Release Notes 12.9 documentation
各 GPU 支持的 CUDA 版本 gpu cuda支持列表_mob64ca13ff28f1的技术博客_51CTO博客
NVIDIA GeForce 驱动程序 - N 卡驱动 | NVIDIA
CUDA GPU Compute Capability | NVIDIA Developer
Legacy CUDA GPU Compute Capability | NVIDIA Developer
【位置编码速通】从ROPE到Yarn:通用公式解析长文本大模型的位置编码!_知识图谱_拥抱AGI-MCP技术社区
清华NLP组发布InfLLM:无需额外训练,「1024K超长上下文」100%召回!-腾讯云开发者社区-腾讯云
自定义 C++ 和 CUDA 算子 — PyTorch 教程 2.7.0+cu126 文档 - PyTorch 深度学习库
自定义 Python 算子 — PyTorch 教程 2.7.0+cu126 文档 - PyTorch 深度学习库
PyTorch 自定义算子 — PyTorch 教程 2.7.0+cu126 文档 - PyTorch 深度学习库
PyTorch 源码解读之 :揭秘 C++/CUDA 算子实现和调用全流程-CSDN博客
PyTorch扩展自定义PyThon/C++(CUDA)算子的若干方法总结 - 知乎
pytorch自定义算子实现详解及反向传播梯度推导 - 知乎
【pytorch扩展】CUDA自定义pytorch算子(简单demo入手)_pytorch_木盏-AI编程社区
pytorch自定义算子并导出onnx计算图详细代码教程_pytorch输出模型的算子图结构-CSDN博客
Pytorch算子扩展详细例程(前向+反向) - BrianX - 博客园
【pytorch】解决pytorch:Torch not compiled with CUDA enabled-阿里云开发者社区
错误Torch not compiled with CUDA enabled解决方法附CUDA安装教程及Pytorch安装教程-CSDN博客
- Title: llm learning
- Author: Ethereal
- Created at: 2025-04-06 17:07:30
- Updated at: 2025-06-11 15:42:29
- Link: https://ethereal-o.github.io/2025/04/06/llm-learning/
- License: This work is licensed under CC BY-NC-SA 4.0.