3fs learning

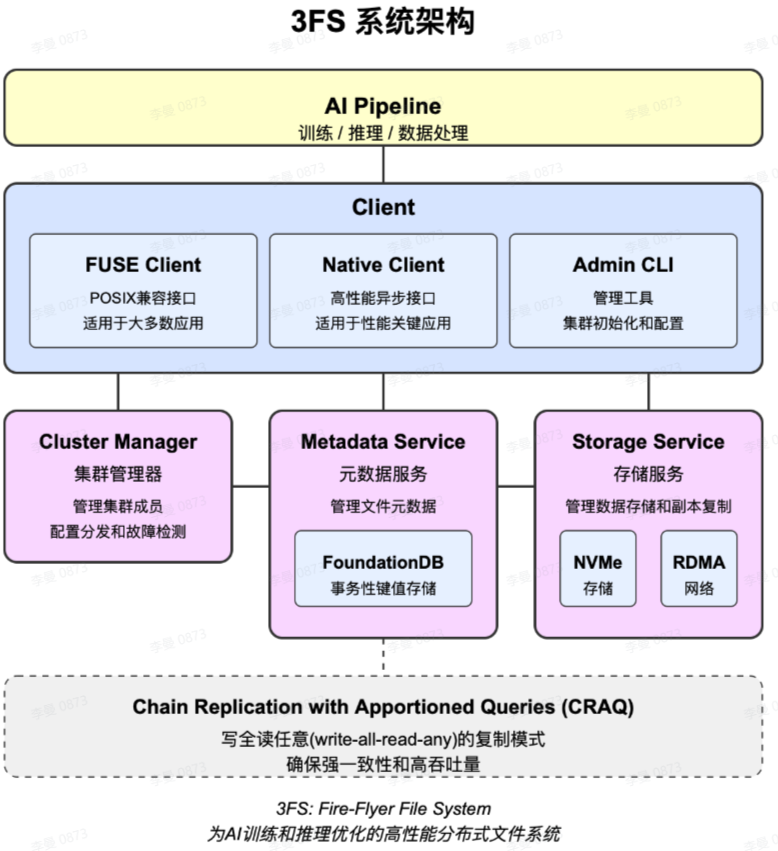
1. 设计
1.1 架构
1.1.1 客户端
1.1.1.1 简介
fuse(需要多次内核态和用户态拷贝,多线程锁抢占性能不佳)
Native client(USRBIO)
File metadata 仍然走fuse daemon流程(例如open/close/stat)。
数据通路走native client:自己开发的library动态库
每个 USRBIO 实例使用一个 Iov 文件和一个 Ior 文件
- Iov 文件用来作为读写数据的 buffer
- 用户提前规划好需要使用的总容量
- 文件创建之后 FUSE Daemon 将该其注册成 RDMA memory buffer,进而实现整个链路的零拷贝(进而加上与服务端的零拷贝)
- Ior 文件用来实现 IoRing
- 用户提前规划好并发度
- 在整个文件上抽象出了提交队列和完成队列,具体布局参考上图
- 文件的尾部是提交完成队列的信号量,FUSE Daemon 在处理完 IO 后通过这个信号量通知到用户进程
- Iov 文件用来作为读写数据的 buffer
一个挂载点的所有 USRBIO 共享 3 个 submit sem 文件
这三个文件作为 IO 提交事件的信号量(submit sem),每一个文件代表一个优先级
一旦某个 USRBIO 实例有 IO 需要提交,会通过该信号量通知到 FUSE Daemon
所有的共享内存文件在挂载点 3fs-virt/iovs/ 目录下均建有 symlink,指向 /dev/shm 下的对应文件。
- shm通过mmap创建,但是没有DMA技术,因此依旧与文件类型相似,需要经过page cache

1.1.1.2 扩展
DMA
| 方面 | 普通文件mmap | DMA设备mmap | 匿名页mmap |
|---|---|---|---|
| 共享媒介 | 磁盘文件 | 物理DMA缓冲区 | 物理内存页 |
| 持久性 | 持久化到磁盘 | 进程运行期间 | 进程运行期间 |
| 亲缘关系 | 任意进程 | 任意进程 | 主要是父子进程 |
| 性能 | 磁盘I/O速度 | 内存总线速度 | 内存总线速度 |
| 同步机制 | 文件锁、信号量 | 自定义驱动同步 | 进程间同步原语 |
以下是一个使用DMA(直接内存访问)技术的C++代码示例,展示了如何在内存和I/O设备之间进行DMA传输:
1 |
|
这个代码示例演示了DMA技术的几个关键方面:
- DMA缓冲区管理:分配和释放用于DMA传输的物理连续内存
- 传输控制:启动内存到设备、设备到内存的DMA传输
- 地址管理:处理虚拟地址和物理地址的转换
实际系统中的注意事项:
在真实系统中,DMA操作通常需要:
- 内核驱动支持
- 物理地址的正确获取(通过DMA API)
- 缓存一致性处理(
dma_sync_*函数) - 中断处理完成通知
Linux内核中的实际DMA API包括:
dma_alloc_coherent()- 分配DMA一致性内存dma_map_single()- 映射单个缓冲区用于DMAdma_unmap_single()- 取消映射
编译时需要链接相关库,在实际嵌入式系统中可能需要交叉编译。
1.1.2 服务端
cluster manager:集群状态管理,使用例如etcd等保证,实际使用FoundationDB 。
meta service:使用FoundationDB存储元数据。
storage service:利用Chain Replication with Apportioned Queries保证一致性。
1.2 无缓存(针对大模型场景随机读设计,缓存失效)
在存储系统发展的早期,DRAM 缓存加 HDD 是主流方案,缓存设计弥补了硬件性能的巨大差距。随着 SSD 的引入,DRAM+SSD 的组合成为优化热点数据的利器。然而,全闪存时代的到来让复杂的缓存机制逐渐成为瓶颈。NVMe SSD 的超高性能,使得 DRAM 缓存在某些场景下反而拖慢了系统效率。
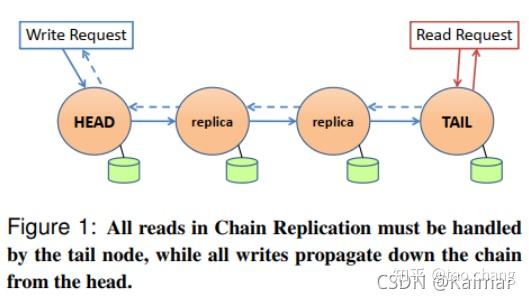
1.3 链式(CRAQ )
1.3.1 具体操作流程
CARQ标准实现写操作流程:
- 客户端把请求发给chain中的head target.
- head target本地执行完写请求后,把请求转发给 second target, second target同样先完成本地写操作后转发tail target.
- tail target 写成功后,会返回ack给前一个target,同样的ack最后返回给head target.
- head target返回给client,应答客户端成功。
3FS的的具体写操作
- storage service接收到write request后,需要检查request带的chain的版本是否是本地最新的版本。如果不是,拒绝该write请求。
- 写操作:target service数据通过RDMA Read操作实现,也就说是通过pull的方式拉取的。
- 不支持对同一个chunk的并发操作。在head target实现对同一个chunk的并发操作的串行访问:当数据写入到target的memory buffer中时,会对该chunk加lock锁住。
- 每个storage service节点上可能存在同一个chunk的两个版本:committed version和 pending version. 版本号都是单调增加的:pending version = committed version + 1
- 在tail target,如果写操作成功,更新commited version为最新的pending version,并返回给前一个(predecessor) target
- 当每个target收到后面(successor)target的成功的ack返回消息,committed version就会变为最新的pending version,并把ack信息继续返回给predecessor target,本地的chunk lock会被释放。
- head target会做同样的操作:修改commited version,释放chunk lock,返回客户端写操作成功的ack消息。
3FS读操作
3FS的读操作可以发送给任意一个chunk副本:
当storage service收到读请求,检查如果对应的data chunk只有一个committed version,就把该版本的数据直接返回给client
NodeX 检查本地 commitVer 和 updateVer 是否相等;
- 步骤 2.1:如果不等,说明有其它 flying 的写请求,通知 Client 重试;
- 步骤 2.2:如果相等,则从本地 chunk 读取数据,并通过 RDMA 写给 Client;
和原始的CRAQ不同,3FS的实现并没有去tail target上去查询确认版本信息。而是提供了两个选项:
直接返回给客户端一个special status code,用户等一段时间后去重试。
客户端对数据一致性要求不敏感,可以直接返回pending version版本的数据给客户端。
错误处理
如果chain中的target故障,就把该target从chain中删除,然后请求重试。
3FS系统中的具体处理方法是把故障的target添加到chain链的末尾并标记为offline状态。
1.3.2 优化
写操作顺序确认(Write-All):虽然写操作需沿链顺序传播到所有节点,但RDMA的特性显著优化了这一过程:
RDMA的单边操作(One-Sided):节点间通过RDMA直接写入下一节点的内存,无需目标节点CPU介入,降低写延迟。
流水线化传输:链中节点可并行处理RDMA写入请求,利用高带宽网络实现高效流水线,减少整体写时延。
读操作完全卸载:由于读请求由任意节点直接通过RDMA响应,主机的CPU无需处理网络协议栈,释放计算资源用于其他任务(如元数据管理或写协调)。
批量处理与高效同步:RDMA支持大规模并发数据传输,CRAQ的版本控制机制(如元数据一致性标记)可快速同步,避免传统网络协议中的ACK风暴。
1.3 小文件以及布局
- 布局
1.4 数据恢复
存储服务崩溃、重启、介质故障,对应的存储 Target 不参与数据写操作,会被移动到 chain 的末尾。
- 数据恢复流程
- 步骤 1:Local Node 向 Remote Node 发起 meta 获取,Remote Node 读取本地 meta;
- 步骤 2:Remote Node 向 Local Node 返回元数据信息,Local Node 比对数据差异;
- 步骤 3:若数据有差异,Local Node 读取本地 chunk 数据到内存;
- 步骤 4:Remote Node 单边读取 Local Node chunk 内存数据;
- 步骤 5:Remote Node 申请新 chunk,并把数据写入新 chunk。
- Sync Data 原则:
- 如果 chunk Local Node 存在 Remote Node 不存在,需要同步;
- 如果 Remote Node 存在 Local Node不存在,需要删除;
- 如果 Local Node 的 chain version 大于Remote Node,需要同步;
- 如果 Local Node 和Remote Node chain version 一样大,但是 commit version 不同,需要同步;
- 其他情况,包括完全相同的数据,或者正在写入的请求数据,不需要同步。
1.5 3FS 如何优化 KV Cache?
存储容量扩展性(分离式架构核心价值)
通过存储计算分离,3FS 可将 KV Cache 存储在专用存储节点池而非 GPU 显存/DRAM 中
单节点可支持 TB 级缓存容量(DRAM 方案通常<1TB),允许部署千亿参数模型
典型案例:单个 A100 GPU 显存仅 80GB,而 3FS 集群可线性扩展至 PB 级
高吞吐访问(RDMA + Direct I/O 的组合优势)
RDMA 网络提供 100Gbps+ 带宽和 μs 级延迟,相比 TCP/IP 网络延迟降低 10 倍
Direct I/O 绕过内核缓存,使 4KB 随机读取延迟稳定在 20μs 以内(传统方案受内核调度影响可能达 100μs+)
实测数据:在 8 节点集群中实现 800GB/s 聚合带宽,满足千卡集群的 KV 读取需求
一致性保障(CRAQ 协议的独特价值)
链式复制确保所有存储节点数据强一致,避免多副本场景下的数据版本冲突
写操作通过链式提交(Node1→Node2→…→NodeN),读操作可从任意副本读取最新已提交数据
对比实验:在 10% 写负载下,CRAQ 的读取吞吐比 Raft 高 3.2 倍
和原始的CRAQ不同,3FS的实现并没有去tail target上去查询确认版本信息。而是提供了两个选项:
直接返回给客户端一个special status code,用户等一段时间后去重试。
客户端对数据一致性要求不敏感,可以直接返回pending version版本的数据给客户端。
利用RDMA,解除CPU占用
小文件
FFRecord
- 避免大量的小文件,所有的样本数据在一个或多个大文件里
其他优化
- 数据读取模式适配:任何任务从3FS上读取数据,要尽可能让64个存储服务节点能同时读取数据,进而降低单存储节点的带宽需求。我们把块大小缩小到 512KB,并且增加了一个文件分布到的服务器数目的控制,最终成功解决了这个问题。
- 流量分类控制:infiniband,进行分类,将流量打满
- 客户端内存优化:减少用户态内核态拷贝
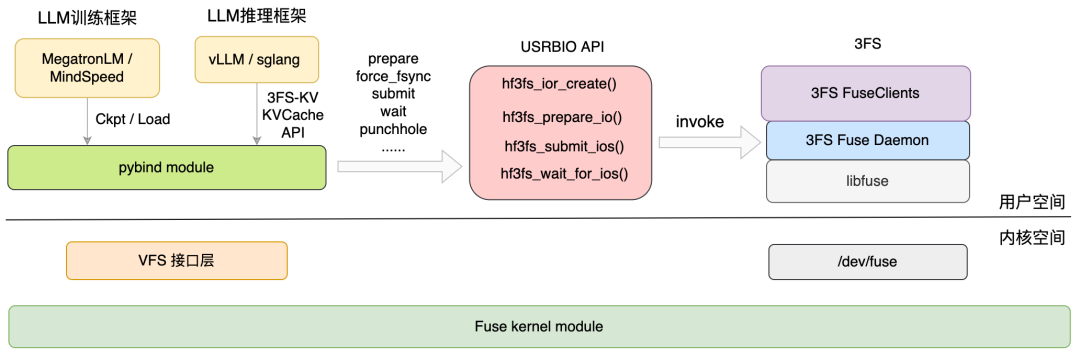
1.6 3FS-KV接口
1.6.1 概览
接入vllm
类似kv,通过USRBIO接口
kvcache index(meta data)放在内存中
周期性更新,但是不需要保证最新,因为可以通过计算获取
也要持久化
kvcache data放在3FS中,通过USRBIO访问
架构图可以参考DeepSeek 3FS 架构分析和思考(上篇) - 文章 - 开发者社区 - 火山引擎
特点:
只对data负责,metadata优先存放在内存中
允许多进程并发提交任务,但是只有3fs自己才可以写入cqe(因此cqe的sem是设计在进程空间内部的,sqe的sem可以通过文件获取)
用户预先指定ring buffer大小
sqe和cqe中只有指针,通过共享内存来减少fuse进程与用户进程数据拷贝
1.6.2 入口
python接口:hf3fs_fuse/io.py
USRBIO原本接口:src/lib/api/hf3fs_usrbio.h
提供iov和ior接口,但是其中Hf3fsIorHandle被置为void*
1.6.3 数据结构设计
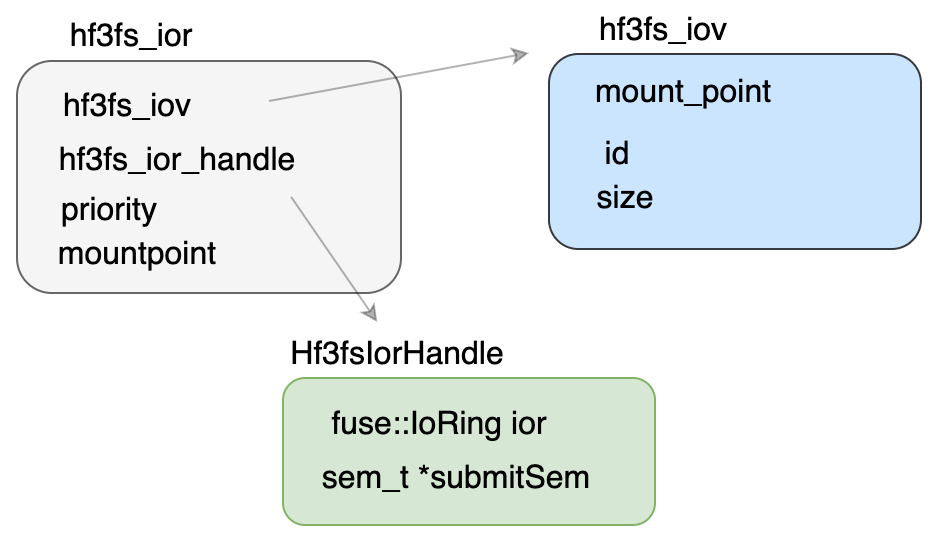
IoRing实现位置:3FS/src/fuse/IoRing.h at 0fd4d9b308f0d7632c6566a881d0fc9ee0584708 · deepseek-ai/3FS
允许并发提交,不允许并发准备(初始化)
1.6.4 流程
例子:3FS/src/lib/api/UsrbIo.md at 0fd4d9b308f0d7632c6566a881d0fc9ee0584708 · deepseek-ai/3FS
调用hf3fs_iovcreate/hf3fs_iovopen/hf3fs_iovwrap来初始化iov区域
->调用hf3fs_iovcreate_general初始化iov区域,取决于是否是numa分配的
调用hf3fs_iorcreate创建ior
->调用hf3fs_iorwrap包装Hf3fsIorHandle
->调用IoRing初始化buffer,其中通过ringMarkerSize()对齐,然后前四个分别是sqe的头尾和cqe的头尾。然后根据传入的size初始化后面size大小的sqe和cqe的entries。然后初始化cqe的sem
->调用cqeSem初始化Hf3fsIorHandle中的submit_sem,submit_sem将从文件中读取,因此其为共享的
调用hf3fs_reg_fd将mount文件传递给3fs
调用hf3fs_prep_io将数据指针拷贝到sqe中(ring.addSqe())
调用hf3fs_submit_ios提交io请求(通过submit_sem通知3fs提交)
调用hf3fs_wait_for_ios等待处理完成(循环等待,一旦完成就拷贝,并调用hf3fs_submit_ios通知3fs更新cqe中的available slots
实现中使用了协程,参考Folly Coroutines Cancellation 的实现 | SF-Zhou’s Blog
2. 思考
2.1 分层kv-cache
3FS提供kv-cache的来源,本地nvme作为kv-cache的缓存,一级位于显存中。使用类似vllm的方式加载或分配kv-cache。
2.2 向量索引
使用向量数据库索引,根据索引拉取3FS的kvcache。
2.2.1 基于树的索引
KD-Tree (K-Dimensional Tree)
原理:递归地将数据空间沿坐标轴分割成超矩形区域,构建二叉树。
优点:适合低维数据(维度 < 20),支持精确搜索。
缺点:高维数据性能急剧下降(“维度灾难”)。
应用场景:小规模低维数据集(如地理坐标搜索)。
Ball Tree
原理:将数据划分为嵌套的超球体,减少距离计算次数。
优点:相比 KD-Tree,在高维数据中表现更好。
缺点:构建和查询成本较高,适合中等维度。
应用场景:中等维度数据(如特征向量分类)。
Annoy (Approximate Nearest Neighbors Oh Yeah)
原理:通过随机投影构建多棵树,利用投票机制提升搜索效率。
优点:内存占用低,支持并行查询。
缺点:需要调参(树的数量、搜索节点数)。
应用场景:中等规模高维数据(如 Spotify 音乐推荐)。
2.2.2 基于哈希的索引
LSH (Locality-Sensitive Hashing)
原理:通过哈希函数将相似向量映射到相同桶中,牺牲精度换速度。
优点:查询速度快,适合超大规模数据。
缺点:参数敏感,召回率较低。
变体:Multi-probe LSH(提升召回率)。
应用场景:海量数据快速粗筛(如去重、预过滤)。
2.2.3 基于图的索引
HNSW (Hierarchical Navigable Small World)
原理:构建多层图结构,上层为稀疏图用于快速导航,下层为稠密图用于精细搜索。
优点:高召回率、低延迟,支持动态更新。
缺点:内存占用较高。
应用场景:高性能实时搜索(如 Milvus、Elasticsearch)。
NSW (Navigable Small World)
原理:单层图结构,通过贪心算法逐步逼近目标节点。
优点:实现简单,适合中小规模数据。
缺点:性能随数据量增长下降明显。
应用场景:小规模实时搜索。
2.2.4 基于量化的索引
PQ (Product Quantization)
原理:将高维向量切分为子向量,分别量化并构建码本,用笛卡尔积压缩向量。
优点:大幅减少内存占用,适合超大规模数据。
缺点:量化误差可能影响精度。
应用场景:大规模图像检索(如 Facebook Faiss)。
IVF (Inverted File Index)
原理:先聚类(如 K-Means),再对每个簇构建倒排索引,搜索时仅遍历最近簇。
优点:结合聚类加速,适合非均匀分布数据。
缺点:聚类质量影响性能。
变体:IVF-PQ(结合量化进一步压缩)。
应用场景:大规模相似性搜索(如 Faiss 的 IVF 系列)。
2.3.5 混合与优化方案
SCANN (Scalable Nearest Neighbors)
原理:结合树、哈希和量化,动态选择最优搜索路径。
优点:平衡速度与精度,适合超大规模数据。
应用场景:Google 的大规模向量检索。
DiskANN
原理:结合图索引与磁盘存储优化,减少内存依赖。
优点:支持内存受限场景。
应用场景:十亿级数据检索(如微软 Bing 搜索)。
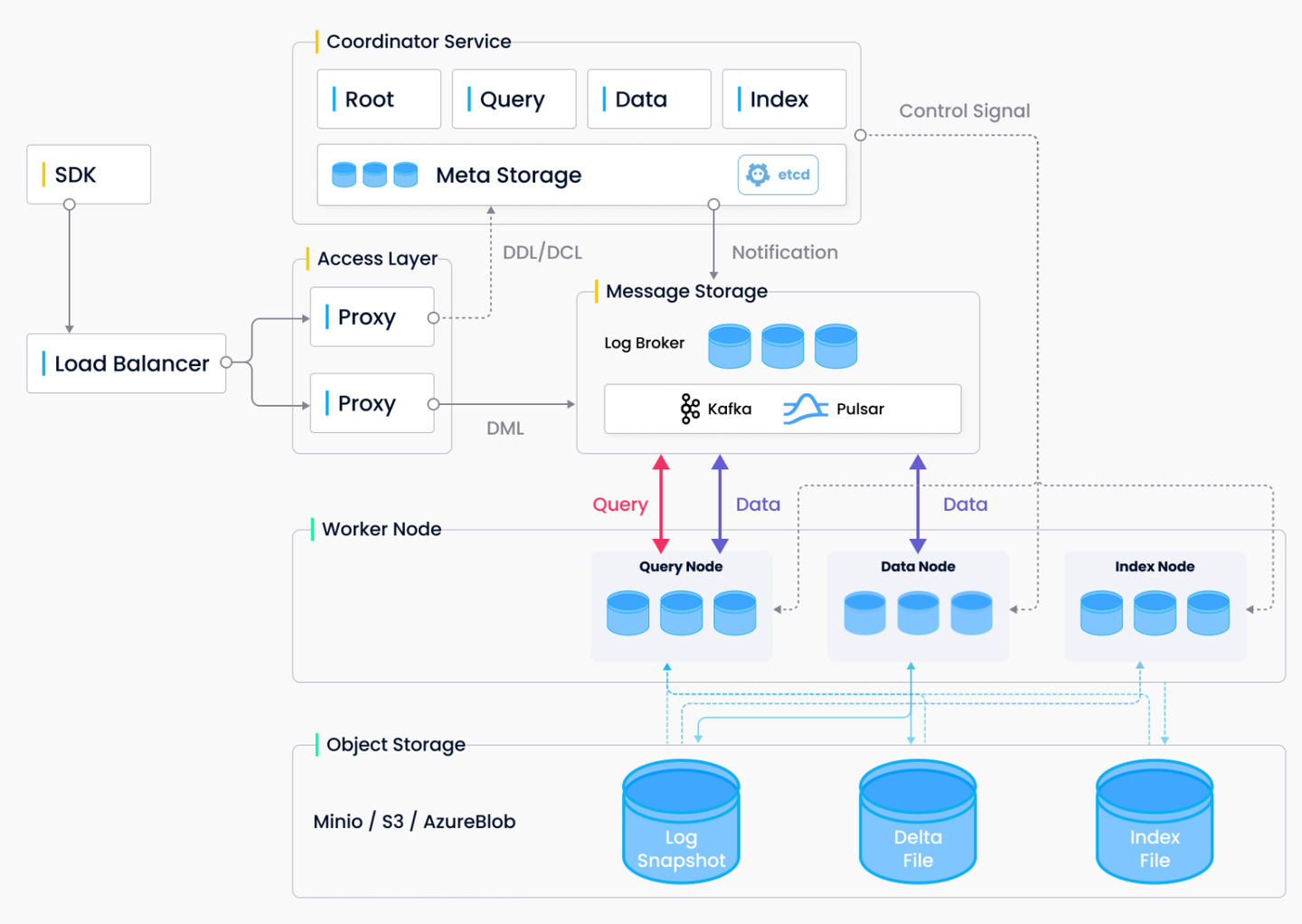
2.3 milvus
利用其他数据库、消息中间件、向量算法库构建向量数据库
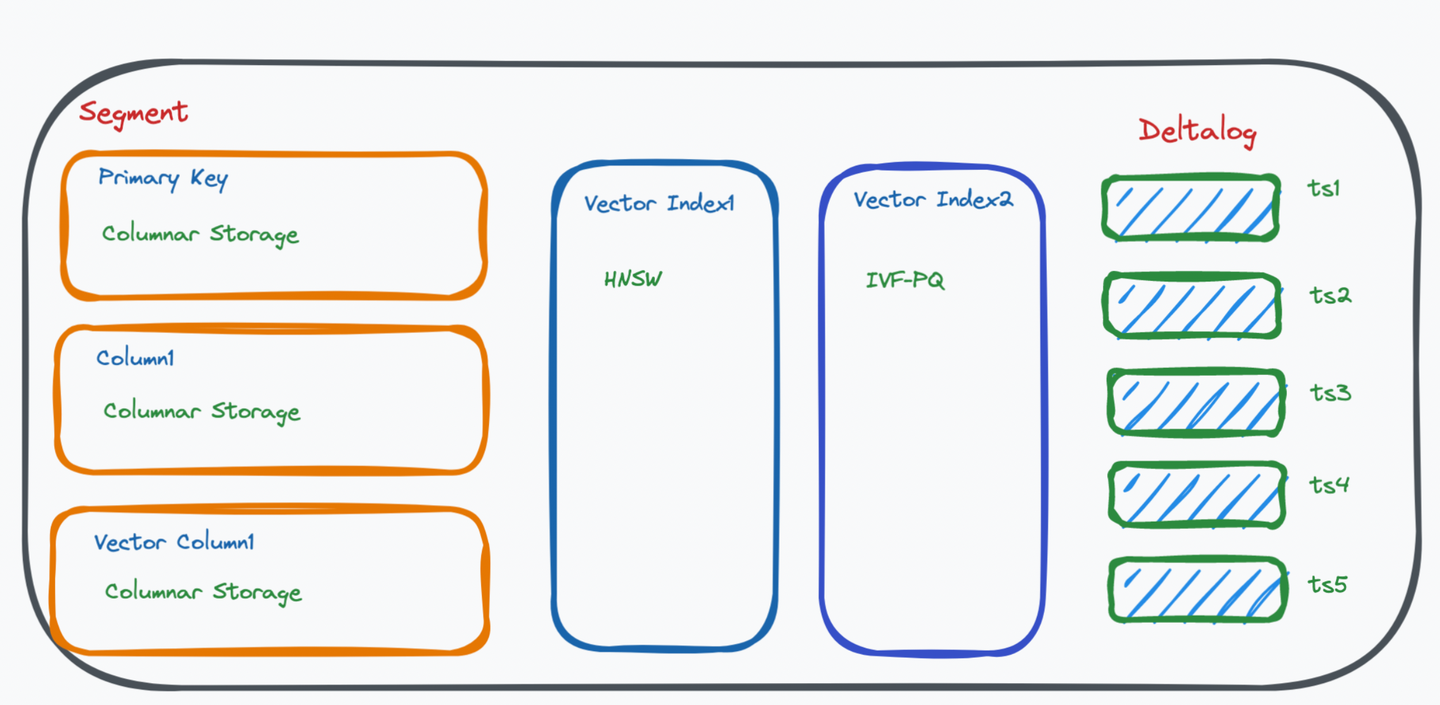
提供分片能力:分shard(自动)、partition(通过键值分区)、segment(最小粒度)
逻辑:
slow path:先放入DataNode存储,然后离线转入IndexNode构建索引,构建结束之后转入QueryNode提供查询服务
fast path:直接转入QueryNode提供查询服务
参考
3FS/docs/design_notes.md at main · deepseek-ai/3FS
Folly Coroutines Cancellation 的实现 | SF-Zhou’s Blog
DeepSeek 3FS:端到端无缓存的存储新范式 - 知乎
DeepSeek Fire-Flyer File System(3FS) - 知乎
DeepSeek开源周 Day05:从3FS盘点分布式文件存储系统-腾讯云开发者社区-腾讯云
DeepSeek 3FS 架构分析和思考(上篇) - 文章 - 开发者社区 - 火山引擎
DeepSeek文件系统3FS设计文档-中文翻译-解读_deepseek 3fs 设计文档-CSDN博客
RAG搭建中,如何选择最合适的向量索引? - Zilliz 向量数据库
向量数据库(三)向量数据库的底层架构及HNSW等索引算法讲解 - 星环开发者社区
1W2000字 一文读懂向量数据库:原理、索引技术与选型指南 - 知乎
LLM-向量数据库中的索引算法总结_向量数据库索引-CSDN博客
向量数据库(第 3 部分):并非所有索引都是一样的 - 知乎
草履虫都看得懂的向量数据库教程,一文就够了_向量数据库使用-CSDN博客
为AI而生的数据库:Milvus详解及实战_向量数据库 milvus-CSDN博客
云原生向量数据库Milvus知识大全,看完这篇就够了[基本概念、系统架构、主要组件、应用场景]-腾讯云开发者社区-腾讯云
Milvus向量数据库全面解析:架构、原理与实践指南-百度开发者中心
How does KVCache Client works on 3FS? · Issue #109 · deepseek-ai/3FS
陈巍:DeepSeek 开源Day(5)3FS&smallpond深入分析(收录于:DeepSeek技术详解系列) - 知乎
3FS/src/lib/rs/hf3fs-usrbio-sys/src/lib.rs at main · deepseek-ai/3FS
3FS系列(三):从源码到实测:3FS USRBIO静态库的编译与性能体验 | 机器之心
3FS/src/lib/api/UsrbIo.md at main · deepseek-ai/3FS
DeepSeek 3FS解读与源码分析(5):客户端解读_usrbio-CSDN博客
3FS/hf3fs_fuse/io.py at 0fd4d9b308f0d7632c6566a881d0fc9ee0584708 · deepseek-ai/3FS
3FS/src/lib/api/hf3fs_usrbio.h at 0fd4d9b308f0d7632c6566a881d0fc9ee0584708 · deepseek-ai/3FS
3FS/src/fuse/IoRing.h at 0fd4d9b308f0d7632c6566a881d0fc9ee0584708 · deepseek-ai/3FS
3FS/src/lib/api/UsrbIo.cc at 0fd4d9b308f0d7632c6566a881d0fc9ee0584708 · deepseek-ai/3FS
Folly Coroutines Cancellation 的实现 | SF-Zhou’s Blog
AI训练存储方案选谁?DeepSeek 3FS与JuiceFS的全面对比|调用|磁盘|拷贝|元数据|ai训练|inode|命令提示符_网易订阅
- Title: 3fs learning
- Author: Ethereal
- Created at: 2025-04-12 15:16:42
- Updated at: 2025-11-16 20:28:30
- Link: https://ethereal-o.github.io/2025/04/12/3fs-learning/
- License: This work is licensed under CC BY-NC-SA 4.0.