dynamo learning

1. 背景
vllm使用pagedAttention(LLM(17):从 FlashAttention 到 PagedAttention, 如何进一步优化 Attention 性能 - 知乎 )加速推理,但是其没有做到以下几点:
| 内容 | 参考 |
|---|---|
| GPU利用率(PD分离) | DistServe |
| 智能路由(动态vllm的worker选取) | DeepSeek |
| 内存管理(缓存管理,将KVcache卸载至SSD,参考3FS) | Mooncake, AIBrix, LMCache |
| 请求量波动的处理(NIXL) | AzureTrace |
因此,它是参考现在DistServe 、Mooncake、Deepseek 这几个PD分离架构的分布式推理系统的产物。它是一个框架,底层调用了vllm等引擎。
2. 亮点
- GPU 资源利用率低
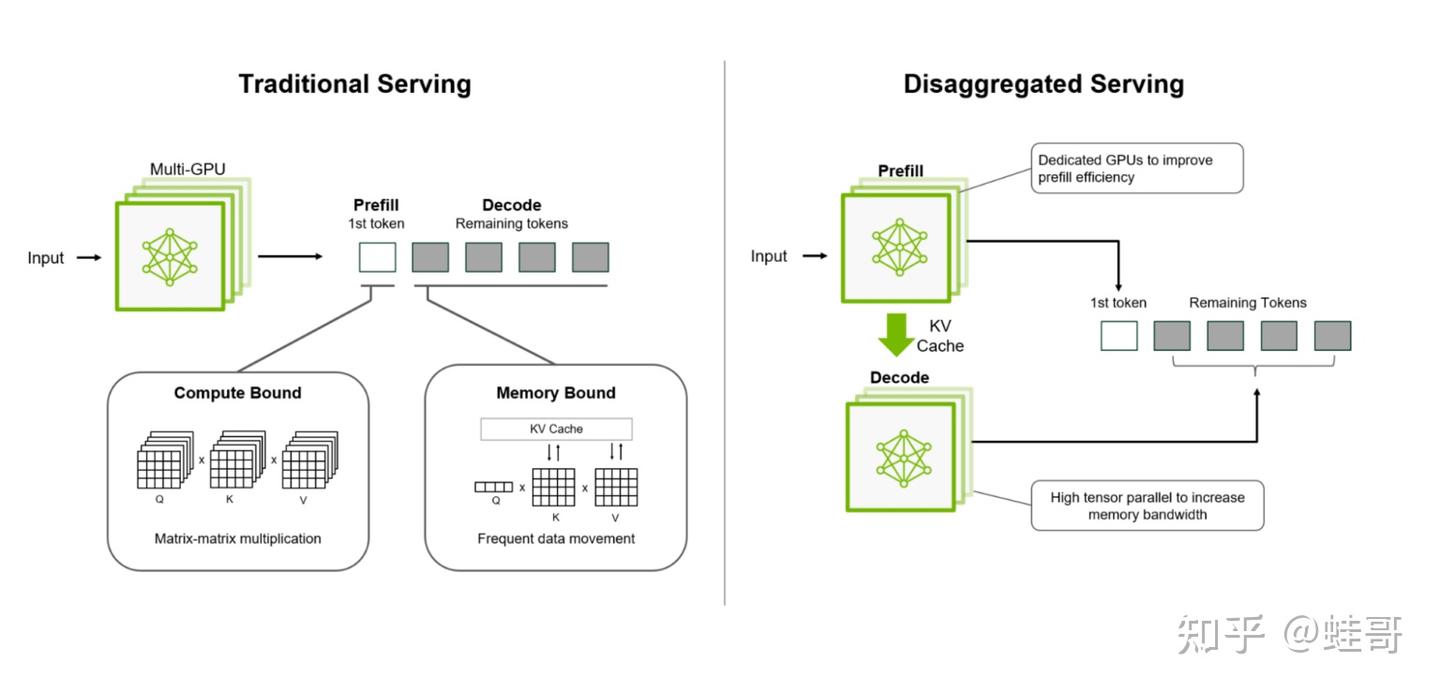
传统推理流程里,预填充(Prefill)计算量大,而解码(Decode)又容易卡住,导致GPU资源浪费。Dynamo 通过 Prefill & Decode 解耦,让GPU分工更合理,单节点GPU吞吐提升30%,多节点吞吐直接翻倍。
-> 解耦推理(Disaggregated Serving),Prefill & Decode分开处理,优化GPU资源利用率,吞吐提升30%-2X。
在Dynamo全局资源分配阶段,即由router选择work id的时候,它有一个KV感知(KV Aware)的计算过程。分配work的时候,不但考虑KV cache的匹配度(KV match),还考虑worker的负载(load)。
- KV Cache匹配度,是指目标计算的cache内容和worker中的历史内容有多少匹配,匹配度越高代表可重复利用量越高,则需要计算量越少;
- worker负载:worker内的计算资源的使用量。
- KV缓存计算浪费
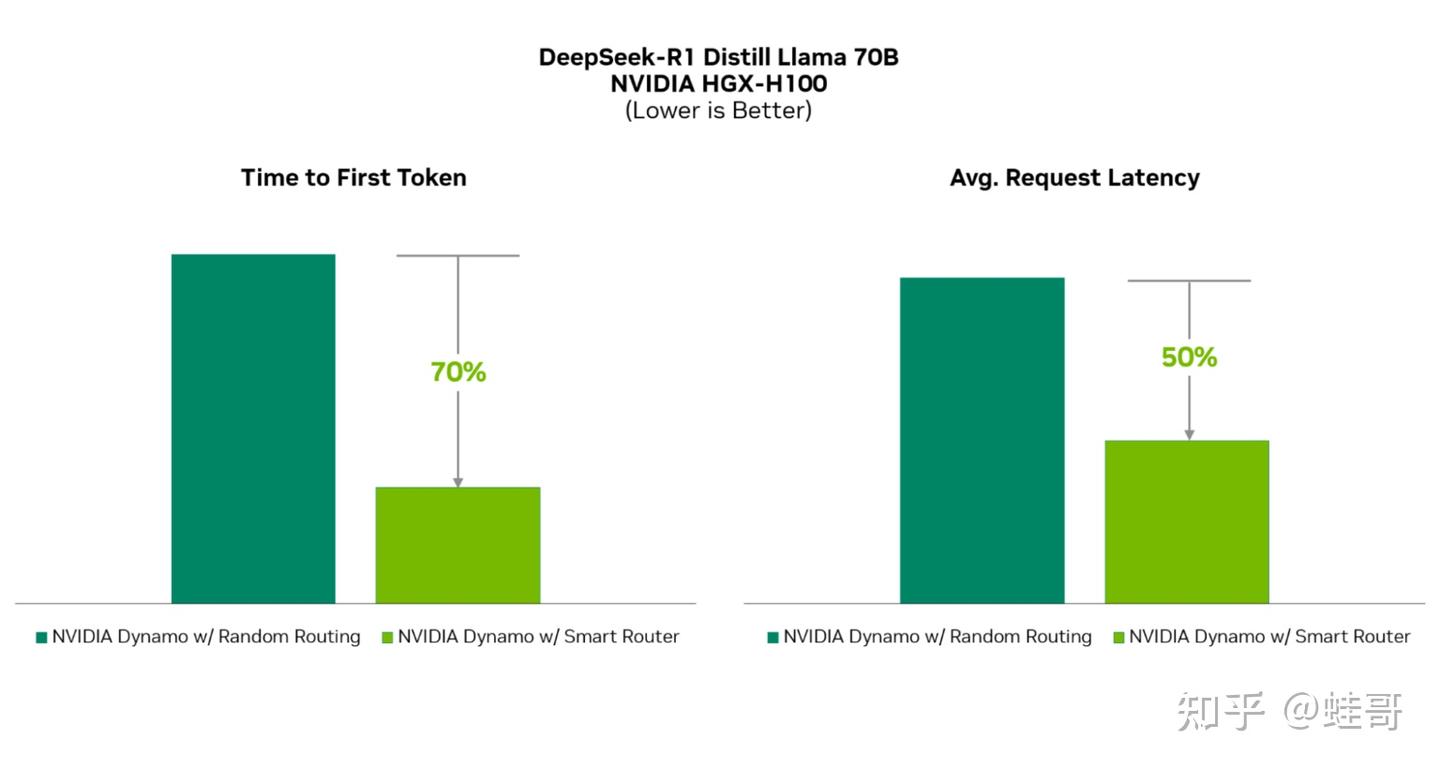
LLM运行时,KV缓存存放的是Transformer模型的中间状态,但很多推理框架乱丢缓存,导致重复计算,增加不必要的延迟。Dynamo 采用 KV 感知的智能路由,直接把请求引导到缓存命中率高的GPU,减少冗余计算。实测首Token时间(TTFT)提高3倍,平均请求延迟减少2倍。
-> 智能路由(Smart Router),采用KV缓存感知调度,减少不必要计算,TTFT 提升 3 倍,平均延迟减少 2 倍。这块的机制也参考了DeepSeek,目前有两种路由策略,相比DeepSeek更通用,但是DeepSeek的策略考虑了细粒度专家EP,对于推R1目前应该还是最佳。
- KV 缓存占用过多GPU显存
LLM 的推理过程中,KV缓存很快会填满GPU,导致推理崩溃或者受限。Dynamo 让KV缓存支持多层存储,比如CPU内存、SSD,甚至远程存储,减少对GPU显存的压力。测试表明,KV缓存转存CPU后,TTFT还能提升40%。通过KVPublisher的事件机制来对KVIndexer进行缓存管理,可以参考MoonCake。
-> 分布式KV缓存管理(KV Cache Manager),支持KV缓存转存 CPU/SSD,减少GPU内存负担,TTFT提升40%。
- 数据传输效率低
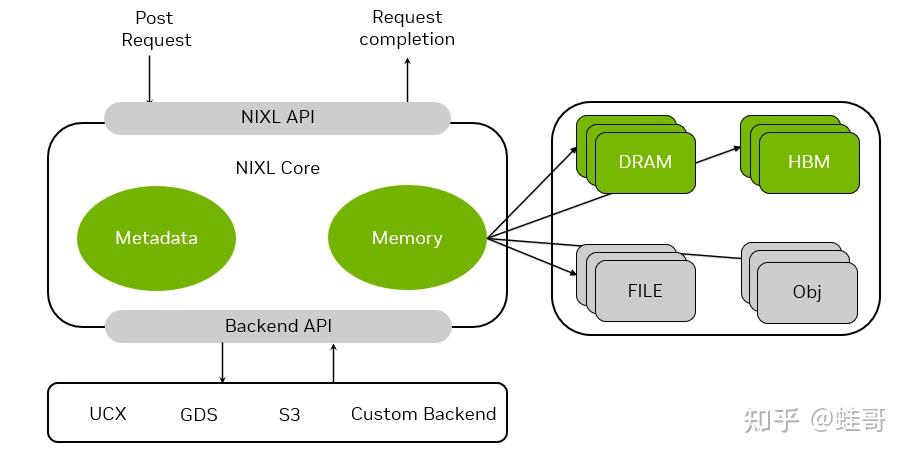
传统的推理数据传输方式低效,特别是在多节点分布式推理时,通信延迟会影响推理速度。Dynamo 采用 NIXL(Nvidia Inference TranXfer Library),优化了多层存储的数据流转,提升整体吞吐量和推理效率。
-> NIXL高效数据传输,自动优化不同存储层级的数据流转,降低数据同步开销,提升整体推理吞吐。
3. DeepSeek开源周
DeepSeek 开源周的五个项目分别是:
- FlashMLA(快速多头潜在注意力):针对大型语言模型推理的高效解码内核,主要提升 GPU 显存利用率和推理速度。
- DeepEP(Expert Parallel):面向混合专家(MoE)模型的高效通信库,加速多 GPU 多节点环境下的通信并降低延迟。
- DeepGEMM:面向通用矩阵乘法(GEMM)的轻量级高性能库,支持 FP8 精度,提升大规模矩阵运算效率。
- DualPipe & EPLB:一套并行训练优化方案,包括 DualPipe(双向流水线并行算法)和 EPLB(专家并行负载均衡),显著提高大模型分布式训练效率。
- 3FS(“源神”分布式文件系统):专为 AI 训练和推理设计的高性能并行文件系统,解决海量数据的高速存取与管理。
参考
5万字详解:深度求索(DeepSeek)开源周报告 - 知乎
使用vllm部署自己的大模型_vllm部署大模型-CSDN博客
在 TKE 上使用 NVIDIA Dynamo 部署 PD 分离的大模型-腾讯云开发者社区-腾讯云
- Title: dynamo learning
- Author: Ethereal
- Created at: 2025-04-24 19:00:33
- Updated at: 2025-04-24 19:42:56
- Link: https://ethereal-o.github.io/2025/04/24/dynamo-learning/
- License: This work is licensed under CC BY-NC-SA 4.0.