gpu learning

1. GPU架构
1.1 架构图
1 | ============================================================ |
1.2 介绍
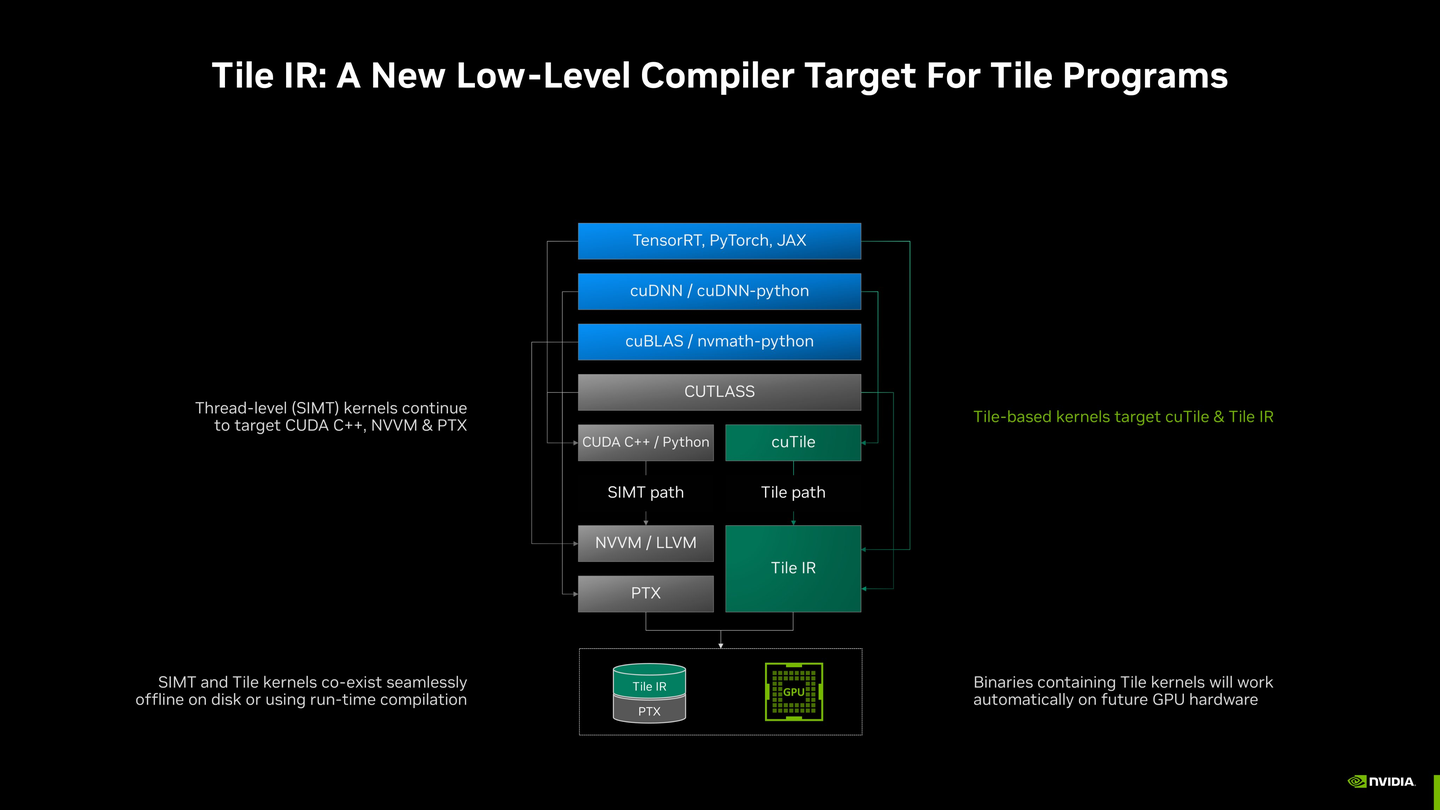
这份架构图展示了 GPU 高性能计算的软件层次结构,突出显示了 NVIDIA 新引入的 Tile IR 路径 与传统 SIMT 路径 的共存,以及 Triton 在其中的角色定位。
I. 顶层:应用与框架 (Application & Frameworks)
这是用户直接交互的最高层,通常使用 Python 或其他高级语言。
代表组件:
TensorRT,PyTorch,JAX。功能: 定义和执行深度学习模型、AI 推理和大规模科学计算任务。它们通过调用底层的库和编译器来获取性能。
II. 中间层:核心库与编程模型 (Core Libraries & Programming Models)
这一层是连接应用与底层硬件优化的关键。
| 区域 | 组件 | 角色与描述 |
|---|---|---|
| 标准库 | cuDNN / cuDNN-python |
深度学习的核心原语库(如卷积、激活函数)。 |
cuBLAS / nvmath-python |
基础线性代数库(如矩阵乘法 GEMM)。 | |
| 低级框架 | CUTLASS | CUDA C++ 模板库,用于手动构建高性能的 GEMM 等瓦片化内核。它为库开发者提供了极致的性能控制。 |
| CUDA C++ | .cu 文件 |
传统的 CUDA 编程文件,包含 __global__ 内核。是 CUTLASS 和 SIMT 内核的宿主环境。需要通过nvcc编译。 |
| Triton (补充) | Triton (JIT 编译器) | 一个高级抽象和 JIT 编译器(Python DSL)。它绕过传统的 CUDA C++/.cu 流程,直接通过编译器生成 PTX 或 SASS。它在抽象级别上与 CUTLASS 竞争,但在实现上与底层编译器交互。 |
Triton 是一种 JIT (Just-In-Time) 编译器,因此它编译出的最终可执行文件通常不会以独立文件的形式存在于您的文件系统中,而是存储在缓存中或直接加载到 GPU 内存中执行。
如果您在问 Triton 编译过程中的关键中间产物或最终目标代码是什么,那么答案涉及编译过程中的多个阶段:
Triton 的编译过程是一个多阶段的流水线,涉及多种形式的中间表示 (IR):
| 阶段 | 产物名称/格式 | 描述 |
|---|---|---|
| I. 源代码 | Python 函数 (带有 @triton.jit 装饰器) |
开发者编写的 Triton DSL 代码。 |
| II. 初始 IR | Triton-IR (.ttir) |
Triton 编译器前端生成的未优化、机器无关的中间表示。 |
| III. 优化 IR | TTGIR (.ttgir) |
经过 Triton 优化器(如循环平铺、内存优化)处理后的 Triton-IR。 |
| IV. LLVM IR | LLVM IR (.llir) |
将 TTGIR 转换为低级别的 LLVM 中间表示,这是通用的编译器基础设施。 |
| V. GPU 汇编 | PTX (.ptx) |
NVIDIA GPU 的并行线程执行(Parallel Thread Execution)虚拟汇编代码。PTX 是一种抽象的 ISA(指令集架构),可以实现跨代 GPU 的兼容性。 |
| VI. 最终目标 | Cubin / SASS | GPU 的最终二进制可执行文件(Cubin 是一种包含 SASS 代码的容器)。SASS (Streaming Assembler) 是特定 GPU 架构的机器码,由 GPU 驱动程序在运行时从 PTX 进一步生成。 |
对于大多数用户而言,Triton 运行时的输出是:
缓存文件(Cache Files):
- 当 Triton 编译一个内核后,它会将生成的 PTX 和/或 Cubin 代码存储在本地的 Triton 缓存目录中(通常是
~/.triton/cache/)。这使得内核在下次运行时可以避免重复编译,直接加载缓存。
- 当 Triton 编译一个内核后,它会将生成的 PTX 和/或 Cubin 代码存储在本地的 Triton 缓存目录中(通常是
直接执行的代码:
- 在 PyTorch 等框架中,Triton 内核是即时编译的。编译完成后,最终的 Cubin/SASS 代码会被加载到 GPU 硬件上,并立即启动执行。这个过程对用户是透明的,不会在您的项目目录中留下可见的
.ptx或.cubin文件。
- 在 PyTorch 等框架中,Triton 内核是即时编译的。编译完成后,最终的 Cubin/SASS 代码会被加载到 GPU 硬件上,并立即启动执行。这个过程对用户是透明的,不会在您的项目目录中留下可见的
因此,Triton 编译出的文件是 GPU 机器码(Cubin/SASS),但它们主要存在于编译器缓存和 GPU 内存中,而不是作为标准的可分发文件存在。
NVIDIA的cuTile 准备阻击 Triton 的DSL,对标Triton。Vendor比用户更容易拿到性能,估计不会开源。

III. 底层:编译器目标与优化路径 (Compiler Targets & Optimization Paths)
从这里开始,程序员的代码被转化为 GPU 硬件可执行的指令。架构图在这里分岔为两条主要路径:SIMT 路径和 Tile 路径。
A. 路径 1:SIMT 路径(传统线程级)
这条路径服务于传统的、线程级 (Thread-level) 的 CUDA 内核,以及那些没有采用复杂瓦片化优化的操作。
输入:
CUDA C++(来自.cu文件)第一步:
NVVM / LLVM- NVVM (NVIDIA Virtual Machine) 是基于 LLVM 的设备代码编译器前端。它对代码进行优化。
第二步: PTX (Parallel Thread Execution)
- 输出 NVIDIA GPU 的虚拟汇编指令。PTX 保证了代码的兼容性,允许同一份二进制文件在不同代 GPU 上运行。
功能: 兼容所有现有 CUDA 代码,是 CUDA 编程模型的基石。
B. 路径 2:Tile 路径(新增瓦片化)
这条路径专门服务于高度优化的、利用现代硬件特性(如 Tensor Cores)的瓦片化 (Tile-based) 内核。
输入:
CUTLASS(通过其新抽象)或专门的瓦片化抽象层 **cuTile**。目标: Tile IR (瓦片中间表示)
Tile IR 是 NVIDIA 新推出的低级编译器目标,它比 PTX 更高级,能更好地表达瓦片化、共享内存协作、异步数据移动等现代 GPU 优化。
其目的是为未来的 GPU 硬件提供更具前瞻性的优化和兼容性。
Tile IR 与 Triton: Triton JIT 编译器最终也会生成 PTX,但理论上,Triton 编译器可以被修改为输出 Tile IR,以利用 NVIDIA 最新的硬件优化,从而取代 Triton 当前的 LLVM IR -> PTX 流程。
IV. 最底层:最终目标与执行 (Final Binary & Execution)
这是 GPU 驱动程序在运行时处理和执行的阶段。
最终二进制: 最终的 GPU 应用程序二进制文件可以无缝包含来自两条路径的代码:
来自 SIMT 路径的 PTX 代码。
来自 Tile 路径的 Tile IR 代码。
驱动程序功能: GPU 驱动程序负责在运行时将 PTX 和 Tile IR 编译/转换为目标硬件的 SASS 机器码(例如 Ampere、Hopper、Blackwell 架构的指令)。
关键优势: 架构图明确指出,包含 Tile 内核的二进制文件将自动在未来的 GPU 硬件上工作,延续了 PTX 作为兼容层的功能。
IV 补充:
SIMT 是 Single Instruction, Multiple Threads(单指令,多线程)的缩写,是 NVIDIA GPU(图形处理器)和 CUDA 编程模型的核心执行范式。
SIMT 是一种并行计算模型,它将底层硬件的 SIMD(单指令,多数据)执行效率与高级的线程级(Thread-level)编程模型结合起来。
SIMT 的核心概念
- 单指令 (Single Instruction)
SIMT 的基础是,在同一时间步内,一组线程(在 NVIDIA GPU 中称为一个 Warp,通常是 32 个线程)将执行相同的指令。这样,只需要一个控制单元来获取、解码和调度指令,从而节省了大量的硬件资源。
- 多线程 (Multiple Threads)
对于程序员来说,他们看到的模型是多线程。您可以像编写普通的多线程 CPU 程序一样,为每个数据元素编写一个独立的、标量(Scalar)的线程代码。
- 简化编程: 程序员无需手动将数据打包成向量(像 SIMD 那样),而是关注单个线程如何处理单个数据。硬件负责将这些线程分组并映射到 SIMD 硬件上。
- Warp (线程束)
SIMT 模型在 GPU 硬件上是通过 Warp(线程束)来实现的:
Warp: 一组(通常是 32 个)并排执行的线程。
锁步执行 (Lock-step Execution): 在一个 Warp 内,所有线程都以相同的步调执行相同的指令。
- 分支发散 (Control Flow Divergence)
这是 SIMT 与严格的 SIMD 的关键区别:
SIMT 的灵活性: 虽然 Warp 内的线程执行相同的指令,但由于每个线程有自己独立的程序计数器(Program Counter)和寄存器状态,它们可以执行不同的代码路径(即遇到
if/else语句时)。性能代价: 当 Warp 内的线程采取不同的分支时,处理器会串行化执行这些分支。例如,如果一半线程走
if分支,另一半走else分支,处理器会先执行if分支并屏蔽掉else线程,然后执行else分支并屏蔽掉if线程。这被称为分支发散 (Divergence),它会降低并行效率。
SIMT 与 SIMD 的主要区别
| 特性 | SIMT (Single Instruction, Multiple Threads) | SIMD (Single Instruction, Multiple Data) |
|---|---|---|
| 编程模型 | 多线程。程序员关注单个标量线程。 | 单线程/向量化。程序员必须手动使用向量指令。 |
| 执行单位 | Warp(线程束)。线程具有独立的状态和程序计数器。 | 向量寄存器/ALU 通道。指令直接作用于向量。 |
| 分支处理 | 允许分支发散,但性能会降低(串行化执行)。 | 较难处理分支。通常需要使用掩码或条件选择指令。 |
| 应用 | GPU 编程(CUDA、OpenCL),擅长高吞吐量计算。 | CPU 向量扩展(如 SSE, AVX, NEON),擅长数据并行。 |
总结来说,SIMT 是 GPU 硬件厂商(主要是 NVIDIA)提供给程序员的一种高级抽象,它让程序员可以像编写传统多线程代码一样,充分利用底层 SIMD 硬件的巨大并行能力。
1.3 例子
1.3.1 Triton
1 | import torch |
1.3.2 cutlass
1 | // 1. 定义 Tiling 策略和数据布局 |
2. Simulator
主要参考(15 封私信 / 80 条消息) Ubuntu 20.04 下安装运行 GPGPU-Sim - 知乎
2.1 安装依赖
基础库
1 | 部署18.04虚拟机 |
下载cudaCUDA Toolkit 11.0 Download | NVIDIA Developer
1 | wget http://developer.download.nvidia.com/compute/cuda/11.0.2/local_installers/cuda_11.0.2_450.51.05_linux.run |
更改~/.bashrc
1 | export CUDA_INSTALL_PATH=/usr/local/cuda |
验证
1 | nvcc -V |
2.2 安装模拟器
1 | wget https://github.com/gpgpu-sim/gpgpu-sim_distribution/archive/refs/tags/v4.0.1.zip |
2.3 运行程序
示例程序hello.cu
1 |
|
编译
1 | nvcc --cudart shared -o hello hello.cu |
运行
1 | cp ~/Programs/gpgpu-sim_distribution/4_0/gpgpu-sim_distribution-4.0.1/configs/tested-cfgs/SM2_GTX480/* ./ |
参考
(15 封私信 / 80 条消息) 新兴 Python 算子开发:Triton、CuTeDSL、MOJO 🔥等概览 - 知乎
(15 封私信 / 80 条消息) OpenAI Triton 入门教程 - 知乎
(15 封私信 / 80 条消息) Ubuntu 20.04 下安装运行 GPGPU-Sim - 知乎
accel-sim/accel-sim-framework: This is the top-level repository for the Accel-Sim framework.
玩转 gpgpu-sim 01记 —— try it-CSDN博客
a1245967/gpgpusim - Docker Image | Docker Hub
accel-sim/accel-sim-framework: This is the top-level repository for the Accel-Sim framework.
accel-sim/accel-sim-framework: This is the top-level repository for the Accel-Sim framework.
(15 封私信 / 80 条消息) CuTeDSL(CUTLASS Python)的初步实践 - 知乎
实用指南:第0记 cutlass 介绍及入门编程使用 - yfceshi - 博客园
(15 封私信 / 80 条消息) CUTLASS 基础介绍 - 知乎
(15 封私信 / 80 条消息) 一文读懂CUDA常用库: CUBLAS、CUDNN、CUTLASS - 知乎
CUDA Toolkit 11.0 Download | NVIDIA Developer
CUDA Toolkit Archive | NVIDIA Developer
CUDA Toolkit 12.4 Update 1 Downloads | NVIDIA 开发者
- Title: gpu learning
- Author: Ethereal
- Created at: 2025-10-25 16:00:21
- Updated at: 2025-10-25 18:05:11
- Link: https://ethereal-o.github.io/2025/10/25/gpu-learning/
- License: This work is licensed under CC BY-NC-SA 4.0.