gpu learning

1. GPU架构
1.1 架构图
1 | ============================================================ |
1.2 介绍
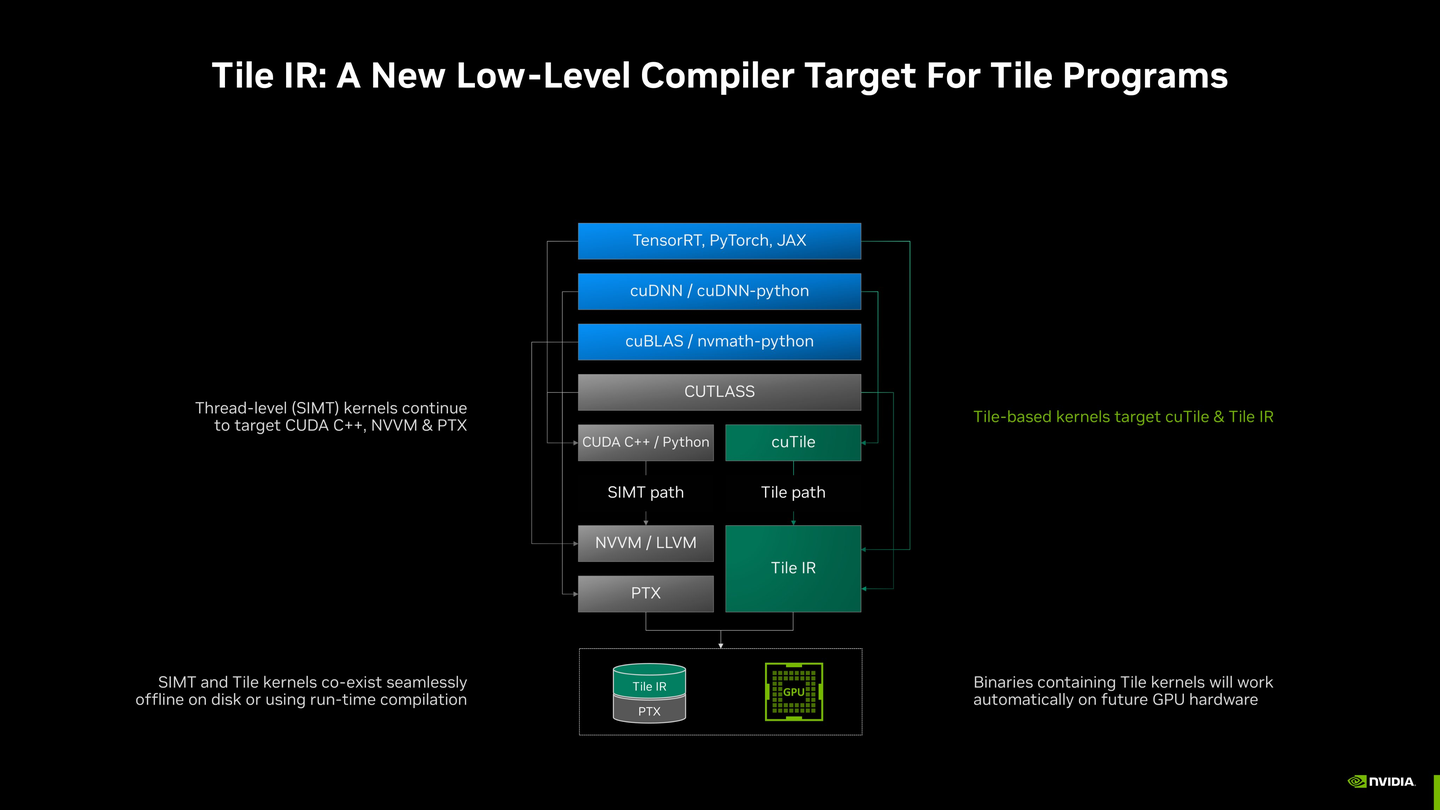
这份架构图展示了 GPU 高性能计算的软件层次结构,突出显示了 NVIDIA 新引入的 Tile IR 路径 与传统 SIMT 路径 的共存,以及 Triton 在其中的角色定位。
I. 顶层:应用与框架 (Application & Frameworks)
这是用户直接交互的最高层,通常使用 Python 或其他高级语言。
代表组件:
TensorRT,PyTorch,JAX。功能: 定义和执行深度学习模型、AI 推理和大规模科学计算任务。它们通过调用底层的库和编译器来获取性能。
II. 中间层:核心库与编程模型 (Core Libraries & Programming Models)
这一层是连接应用与底层硬件优化的关键。
| 区域 | 组件 | 角色与描述 |
|---|---|---|
| 标准库 | cuDNN / cuDNN-python |
深度学习的核心原语库(如卷积、激活函数)。 |
cuBLAS / nvmath-python |
基础线性代数库(如矩阵乘法 GEMM)。 | |
| 低级框架 | CUTLASS | CUDA C++ 模板库,用于手动构建高性能的 GEMM 等瓦片化内核。它为库开发者提供了极致的性能控制。 |
| CUDA C++ | .cu 文件 |
传统的 CUDA 编程文件,包含 __global__ 内核。是 CUTLASS 和 SIMT 内核的宿主环境。需要通过nvcc编译。 |
| Triton (补充) | Triton (JIT 编译器) | 一个高级抽象和 JIT 编译器(Python DSL)。它绕过传统的 CUDA C++/.cu 流程,直接通过编译器生成 PTX 或 SASS。它在抽象级别上与 CUTLASS 竞争,但在实现上与底层编译器交互。 |
Triton 是一种 JIT (Just-In-Time) 编译器,因此它编译出的最终可执行文件通常不会以独立文件的形式存在于您的文件系统中,而是存储在缓存中或直接加载到 GPU 内存中执行。
如果您在问 Triton 编译过程中的关键中间产物或最终目标代码是什么,那么答案涉及编译过程中的多个阶段:
Triton 的编译过程是一个多阶段的流水线,涉及多种形式的中间表示 (IR):
| 阶段 | 产物名称/格式 | 描述 |
|---|---|---|
| I. 源代码 | Python 函数 (带有 @triton.jit 装饰器) |
开发者编写的 Triton DSL 代码。 |
| II. 初始 IR | Triton-IR (.ttir) |
Triton 编译器前端生成的未优化、机器无关的中间表示。 |
| III. 优化 IR | TTGIR (.ttgir) |
经过 Triton 优化器(如循环平铺、内存优化)处理后的 Triton-IR。 |
| IV. LLVM IR | LLVM IR (.llir) |
将 TTGIR 转换为低级别的 LLVM 中间表示,这是通用的编译器基础设施。 |
| V. GPU 汇编 | PTX (.ptx) |
NVIDIA GPU 的并行线程执行(Parallel Thread Execution)虚拟汇编代码。PTX 是一种抽象的 ISA(指令集架构),可以实现跨代 GPU 的兼容性。 |
| VI. 最终目标 | Cubin / SASS | GPU 的最终二进制可执行文件(Cubin 是一种包含 SASS 代码的容器)。SASS (Streaming Assembler) 是特定 GPU 架构的机器码,由 GPU 驱动程序在运行时从 PTX 进一步生成。 |
对于大多数用户而言,Triton 运行时的输出是:
缓存文件(Cache Files):
- 当 Triton 编译一个内核后,它会将生成的 PTX 和/或 Cubin 代码存储在本地的 Triton 缓存目录中(通常是
~/.triton/cache/)。这使得内核在下次运行时可以避免重复编译,直接加载缓存。
- 当 Triton 编译一个内核后,它会将生成的 PTX 和/或 Cubin 代码存储在本地的 Triton 缓存目录中(通常是
直接执行的代码:
- 在 PyTorch 等框架中,Triton 内核是即时编译的。编译完成后,最终的 Cubin/SASS 代码会被加载到 GPU 硬件上,并立即启动执行。这个过程对用户是透明的,不会在您的项目目录中留下可见的
.ptx或.cubin文件。
- 在 PyTorch 等框架中,Triton 内核是即时编译的。编译完成后,最终的 Cubin/SASS 代码会被加载到 GPU 硬件上,并立即启动执行。这个过程对用户是透明的,不会在您的项目目录中留下可见的
因此,Triton 编译出的文件是 GPU 机器码(Cubin/SASS),但它们主要存在于编译器缓存和 GPU 内存中,而不是作为标准的可分发文件存在。
NVIDIA的cuTile 准备阻击 Triton 的DSL,对标Triton。Vendor比用户更容易拿到性能,估计不会开源。

III. 底层:编译器目标与优化路径 (Compiler Targets & Optimization Paths)
从这里开始,程序员的代码被转化为 GPU 硬件可执行的指令。架构图在这里分岔为两条主要路径:SIMT 路径和 Tile 路径。
A. 路径 1:SIMT 路径(传统线程级)
这条路径服务于传统的、线程级 (Thread-level) 的 CUDA 内核,以及那些没有采用复杂瓦片化优化的操作。
输入:
CUDA C++(来自.cu文件)第一步:
NVVM / LLVM- NVVM (NVIDIA Virtual Machine) 是基于 LLVM 的设备代码编译器前端。它对代码进行优化。
第二步: PTX (Parallel Thread Execution)
- 输出 NVIDIA GPU 的虚拟汇编指令。PTX 保证了代码的兼容性,允许同一份二进制文件在不同代 GPU 上运行。
功能: 兼容所有现有 CUDA 代码,是 CUDA 编程模型的基石。
B. 路径 2:Tile 路径(新增瓦片化)
这条路径专门服务于高度优化的、利用现代硬件特性(如 Tensor Cores)的瓦片化 (Tile-based) 内核。
输入:
CUTLASS(通过其新抽象)或专门的瓦片化抽象层 **cuTile**。目标: Tile IR (瓦片中间表示)
Tile IR 是 NVIDIA 新推出的低级编译器目标,它比 PTX 更高级,能更好地表达瓦片化、共享内存协作、异步数据移动等现代 GPU 优化。
其目的是为未来的 GPU 硬件提供更具前瞻性的优化和兼容性。
Tile IR 与 Triton: Triton JIT 编译器最终也会生成 PTX,但理论上,Triton 编译器可以被修改为输出 Tile IR,以利用 NVIDIA 最新的硬件优化,从而取代 Triton 当前的 LLVM IR -> PTX 流程。
IV. 最底层:最终目标与执行 (Final Binary & Execution)
这是 GPU 驱动程序在运行时处理和执行的阶段。
最终二进制: 最终的 GPU 应用程序二进制文件可以无缝包含来自两条路径的代码:
来自 SIMT 路径的 PTX 代码。
来自 Tile 路径的 Tile IR 代码。
驱动程序功能: GPU 驱动程序负责在运行时将 PTX 和 Tile IR 编译/转换为目标硬件的 SASS 机器码(例如 Ampere、Hopper、Blackwell 架构的指令)。
关键优势: 架构图明确指出,包含 Tile 内核的二进制文件将自动在未来的 GPU 硬件上工作,延续了 PTX 作为兼容层的功能。
IV 补充:
SIMT 是 Single Instruction, Multiple Threads(单指令,多线程)的缩写,是 NVIDIA GPU(图形处理器)和 CUDA 编程模型的核心执行范式。
SIMT 是一种并行计算模型,它将底层硬件的 SIMD(单指令,多数据)执行效率与高级的线程级(Thread-level)编程模型结合起来。
SIMT 的核心概念
- 单指令 (Single Instruction)
SIMT 的基础是,在同一时间步内,一组线程(在 NVIDIA GPU 中称为一个 Warp,通常是 32 个线程)将执行相同的指令。这样,只需要一个控制单元来获取、解码和调度指令,从而节省了大量的硬件资源。
- 多线程 (Multiple Threads)
对于程序员来说,他们看到的模型是多线程。您可以像编写普通的多线程 CPU 程序一样,为每个数据元素编写一个独立的、标量(Scalar)的线程代码。
- 简化编程: 程序员无需手动将数据打包成向量(像 SIMD 那样),而是关注单个线程如何处理单个数据。硬件负责将这些线程分组并映射到 SIMD 硬件上。
- Warp (线程束)
SIMT 模型在 GPU 硬件上是通过 Warp(线程束)来实现的:
Warp: 一组(通常是 32 个)并排执行的线程。
锁步执行 (Lock-step Execution): 在一个 Warp 内,所有线程都以相同的步调执行相同的指令。
- 分支发散 (Control Flow Divergence)
这是 SIMT 与严格的 SIMD 的关键区别:
SIMT 的灵活性: 虽然 Warp 内的线程执行相同的指令,但由于每个线程有自己独立的程序计数器(Program Counter)和寄存器状态,它们可以执行不同的代码路径(即遇到
if/else语句时)。性能代价: 当 Warp 内的线程采取不同的分支时,处理器会串行化执行这些分支。例如,如果一半线程走
if分支,另一半走else分支,处理器会先执行if分支并屏蔽掉else线程,然后执行else分支并屏蔽掉if线程。这被称为分支发散 (Divergence),它会降低并行效率。
SIMT 与 SIMD 的主要区别
| 特性 | SIMT (Single Instruction, Multiple Threads) | SIMD (Single Instruction, Multiple Data) |
|---|---|---|
| 编程模型 | 多线程。程序员关注单个标量线程。 | 单线程/向量化。程序员必须手动使用向量指令。 |
| 执行单位 | Warp(线程束)。线程具有独立的状态和程序计数器。 | 向量寄存器/ALU 通道。指令直接作用于向量。 |
| 分支处理 | 允许分支发散,但性能会降低(串行化执行)。 | 较难处理分支。通常需要使用掩码或条件选择指令。 |
| 应用 | GPU 编程(CUDA、OpenCL),擅长高吞吐量计算。 | CPU 向量扩展(如 SSE, AVX, NEON),擅长数据并行。 |
总结来说,SIMT 是 GPU 硬件厂商(主要是 NVIDIA)提供给程序员的一种高级抽象,它让程序员可以像编写传统多线程代码一样,充分利用底层 SIMD 硬件的巨大并行能力。
1.3 例子
1.3.1 Triton
1 | import torch |
1.3.2 cutlass
1 | // 1. 定义 Tiling 策略和数据布局 |
2. Simulator
主要参考(15 封私信 / 80 条消息) Ubuntu 20.04 下安装运行 GPGPU-Sim - 知乎
2.1 安装依赖
基础库
1 | 部署18.04虚拟机 |
下载cudaCUDA Toolkit 11.0 Download | NVIDIA Developer
1 | wget http://developer.download.nvidia.com/compute/cuda/11.0.2/local_installers/cuda_11.0.2_450.51.05_linux.run |
更改~/.bashrc
1 | export CUDA_INSTALL_PATH=/usr/local/cuda |
验证
1 | nvcc -V |
2.2 安装模拟器
1 | wget https://github.com/gpgpu-sim/gpgpu-sim_distribution/archive/refs/tags/v4.0.1.zip |
2.3 运行程序
示例程序hello.cu
1 |
|
编译
1 | nvcc --cudart shared -o hello hello.cu |
运行
1 | cp ~/Programs/gpgpu-sim_distribution/4_0/gpgpu-sim_distribution-4.0.1/configs/tested-cfgs/SM2_GTX480/* ./ |
3. 其他知识
3.1 UVM
UVM(Unified Virtual Memory,统一虚拟内存)是 CUDA 提供的一种内存管理机制,允许 CPU 和 GPU 共享同一个虚拟地址空间,使程序员无需手动管理数据在主机内存与设备内存之间的拷贝。
3.1.1 核心概念
在传统 CUDA 编程中,需要显式使用 cudaMalloc + cudaMemcpy 在 Host 和 Device 之间搬运数据。UVM 引入了”托管内存(Managed Memory)”的概念,将内存管理的职责交给 CUDA 运行时和驱动程序:
1 | // 传统方式 |
3.1.2 工作原理
UVM 的核心是按需页面迁移(Demand Paging):
- 当 GPU 访问一个不在 GPU 显存中的页面时,触发缺页中断(Page Fault)。
- CUDA 驱动程序捕获此中断,将对应的内存页从 CPU 内存迁移到 GPU 显存。
- 反之,当 CPU 访问一个在 GPU 显存中的页面时,同样触发迁移。
这种机制在 Pascal 架构(GTX 1080/P100)之后才得到硬件支持,在更早的架构上只是逻辑统一(物理数据仍需拷贝)。
3.1.3 性能优化 API
UVM 提供了两个重要的提示 API 来优化性能,避免频繁的缺页中断:
1 | // 1. 内存访问建议 (Hint):告诉运行时数据的访问模式 |
3.1.4 内存超订阅(Memory Oversubscription)
UVM 支持超订阅,即分配的托管内存总量可以超过 GPU 显存容量。当 GPU 显存不足时,驱动会自动将最近最少使用的页面换出到 CPU 内存,类似操作系统的虚拟内存换页机制。这对于处理超大模型或数据集非常有用,但频繁换页会带来显著的性能损耗。
3.1.5 使用注意事项
| 场景 | 建议 |
|---|---|
| 数据仅被 GPU 访问 | 使用 cudaMemAdviseSetPreferredLocation(GPU) + cudaMemPrefetchAsync |
| 数据被 CPU 和 GPU 交替访问 | UVM 是合适的选择,配合 Prefetch 减少缺页 |
| 追求极致性能 | 建议使用传统显式拷贝,避免缺页开销 |
| 数据量超过显存容量 | UVM 超订阅是主要解决方案 |
3.2 TMA
TMA(Tensor Memory Accelerator,张量内存加速器)是 NVIDIA Hopper 架构(H100)引入的硬件单元,专门用于在全局内存(Global Memory)和共享内存(Shared Memory)之间进行高效的、硬件管理的批量数据搬运。
3.2.1 为什么需要 TMA
在传统的 CUDA 编程中,数据从 Global Memory 搬运到 Shared Memory 的流程是:
- 每个线程计算自己负责加载的内存地址(需要大量寄存器和指令)。
- 每个线程执行
cp.async指令。 - 整个 Warp 协同完成一个 Tile 的搬运。
这种方式的缺点是:地址计算消耗大量寄存器(影响 Occupancy),并且需要 Warp 中的所有线程参与才能完成一次数据搬运。
TMA 将整个过程卸载(offload)给硬件,只需要一个线程(甚至不占用计算资源)即可发起一次完整 Tile 的搬运。
3.2.2 核心特性
- 单线程发起:只需一个线程调用一条指令,即可完成整块 Tile(最高 5D 张量)的异步搬运。
- 硬件地址计算:Tensor descriptor 预先描述了张量的形状、步幅(stride)、数据类型,硬件自动计算地址。
- 异步执行:搬运与计算可以重叠(overlap),使用
mbarrier(内存屏障)进行同步。 - 支持多维度:支持 1D 到 5D 的张量 Tile 拷贝,自然匹配矩阵分块的内存布局。
- 支持 Swizzle:可以在搬运时对数据进行 Swizzle(重排),消除 Shared Memory 的 Bank Conflict。
3.2.3 工作流程
1 | // 1. 在 Host 端创建 Tensor Map(描述符),描述张量的形状和访问方式 |
3.2.4 TMA 与传统 cp.async 的对比
| 特性 | cp.async(传统) |
TMA |
|---|---|---|
| 发起线程数 | 整个 Warp(32线程) | 仅 1 个线程 |
| 地址计算 | 软件(消耗寄存器) | 硬件(Tensor Descriptor) |
| 支持维度 | 1D(线性地址) | 1D ~ 5D |
| Swizzle | 需手动实现 | 硬件内置支持 |
| 同步机制 | cp.async.wait_group |
mbarrier(更灵活) |
| 适用架构 | Ampere(A100)及以上 | Hopper(H100)及以上 |
3.3 拓扑
3.3.1 拓扑架构
PIX
NODE
SYS
3.3.2 区别
- 当使用同一个numa节点时,做内存到CPU内存到拷贝,带宽是52GB/s,说明PCIE没有问题。
- 当使用同一个numa节点时,做CPU内存到内存的RDMA,带宽是32GB/s(因为做同时读写,带宽/2,没有问题)。
- 当使用同一个numa节点时,当从内存向GPU做RDMA时(GPU和内存都在同一个numa下),带宽是22GB/s(首先是同时做读写,带宽/2,此外,受限于NODE架构而更小)。
- 当使用同一个numa节点时,当从GPU向内存做RDMA时(GPU和内存都在同一个numa下),带宽是16GB/s(在前一个基础上,RDMA写要更慢)。
3.4 Warp Specialization
Warp Specialization(Warp 专化)是一种编程范式,将同一个 ThreadBlock 内的不同 Warp 赋予不同的”角色”,典型地分为生产者 Warp(Producer)和消费者 Warp(Consumer),以实现数据搬运与计算的深度流水线重叠。这一范式在 Hopper 架构配合 TMA 使用时达到最佳效果。
3.4.1 传统模式 vs Warp Specialization
传统模式(所有 Warp 职责相同):
1 | 所有 Warp: [Load A] [Load B] → [同步] → [Compute MMA] → [Load A] [Load B] → ... |
所有 Warp 交替执行数据加载和矩阵计算,中间的同步(__syncthreads)导致流水线停顿。
Warp Specialization 模式:
1 | Producer Warp: [TMA Load A0] → [TMA Load B0] → [TMA Load A1] → [TMA Load B1] → ... |
生产者 Warp 专门负责发起 TMA 异步搬运,消费者 Warp 专门负责 Tensor Core 计算,两者通过 mbarrier 进行细粒度同步,真正实现”搬运和计算同时进行”。
3.4.2 核心实现要素
1. 角色划分
通过 warpId 区分 Warp 的角色,让不同 Warp 执行不同的代码路径:
1 | int warp_id = threadIdx.x / 32; |
2. 环形共享内存缓冲区(Circular Buffer / Ping-Pong Buffer)
为了让生产者和消费者能够并行工作,共享内存被划分为多个 Stage(通常2~4个),形成环形缓冲区:
1 | Stage 0: [正在被 Consumer 计算] |
3. mbarrier 同步
mbarrier(Memory Barrier)是 Hopper 引入的细粒度同步原语,替代了传统的 __syncthreads。它允许只在特定 Warp 之间同步,而不是整个 ThreadBlock,大幅减少同步开销。
1 | // Producer 完成一次加载后,通知 Consumer |
3.4.3 性能收益
Warp Specialization 的主要收益来自两方面:
- 计算与搬运重叠:消费者 Warp 在做 MMA 计算时,生产者 Warp 同时在做下一轮数据的 TMA 搬运,极大提升硬件利用率。
- 减少寄存器压力:生产者 Warp 和消费者 Warp 的寄存器使用场景不同,可以在编译器层面分别优化,避免两类操作共用寄存器导致 Occupancy 下降。
这一模式是 H100 上实现接近理论峰值的 GEMM 性能的关键技术之一,FlashAttention-3、CUTLASS 3.x 的 Hopper 内核均大量采用此范式。
3.5 GPTQ和AWQ量化
模型量化是将浮点权重(FP16/BF16)压缩为低比特整数(INT4/INT8)的技术,目的是在保持模型精度的同时,大幅降低显存占用和提升推理吞吐。GPTQ 和 AWQ 是目前最主流的两种 LLM PTQ(训练后量化)方法。
3.5.1 GPTQ(基于 Hessian 的逐层量化)
GPTQ(Generative Pre-Training Quantization)的核心思想是:对每一层权重矩阵,利用二阶梯度信息(Hessian 矩阵)来最小化量化误差。
核心算法:Optimal Brain Quantization(OBQ)
对于权重矩阵 $W$,量化某一列 $w_q$ 时,补偿误差会传播到剩余的未量化列:
$$\delta W = -\frac{(w_q - \text{quant}(w_q))}{[H^{-1}]{qq}} \cdot (H^{-1}){:,q}$$
GPTQ 对列进行顺序量化,每量化一列后,立刻用上述公式补偿剩余列,使整体量化误差最小。
主要特点:
- 使用少量校准数据(通常 128 条样本)计算 Hessian
- 量化粒度:每组(group)权重共享一组量化参数(scale + zero_point),group size 通常为 128
- 支持 INT4、INT3 量化
- 量化速度较慢(需要 Hessian 计算),但精度较高
3.5.2 AWQ(激活感知权重量化)
AWQ(Activation-aware Weight Quantization)的核心洞察是:不是所有权重对模型精度的影响都相同,只有约 1% 的”显著权重”(对应激活值较大的通道)对精度至关重要。
核心思想:
直接对重要权重使用更高精度(不量化)会带来硬件实现的不规则性,AWQ 换了一种思路:通过缩放(scaling)将重要权重的量化误差转移。
对于线性层 $y = Wx$,等价变换:
$$y = (W \cdot \text{diag}(s)^{-1}) \cdot (\text{diag}(s) \cdot x) = W’ \cdot x’$$
通过对激活值较大的通道对应的权重进行放大再量化(量化后再除以放大系数),可以降低重要通道的量化误差,同时保持硬件计算的规整性。
主要特点:
- 不需要反向传播,只需前向校准数据
- 量化速度快,内存占用低
- 通常 AWQ 的精度与 GPTQ 相当甚至更好
- 被 vLLM、TGI 等主流推理框架广泛支持
3.5.3 对比
| 特性 | GPTQ | AWQ |
|---|---|---|
| 理论基础 | 二阶优化(Hessian) | 激活感知缩放 |
| 量化速度 | 较慢(分钟~小时级) | 较快(分钟级) |
| 精度 | 高 | 相当或更好 |
| 推理内核 | ExLlama / GPTQ-for-LLaMA | AWQ CUDA kernel |
| 适用场景 | 追求极致压缩比 | 快速部署、生产推理 |
模型量化操作————GPTQ和AWQ量化 - Big-Yellow-J - 博客园
3.6 MMA
MMA(Matrix Multiply-Accumulate)是 NVIDIA Tensor Core 的核心操作,对应 PTX 指令集中的 mma.sync 指令。Tensor Core 是专用于矩阵乘加运算的硬件单元,从 Volta 架构(V100)开始引入,在 Hopper(H100)上演进到 Wgmma(Warp Group MMA)。
3.6.1 基本概念
Tensor Core 在每个时钟周期内执行一个小型矩阵乘加:
$$D = A \times B + C$$
其中 A、B、C、D 是小型矩阵(Fragment),尺寸取决于数据类型和架构,例如 Volta 上的 m16n16k16(FP16)。
3.6.2 PTX MMA 指令
PTX 中的 mma.sync 指令格式如下:
1 | mma.sync.aligned.m16n8k16.row.col.f32.f16.f16.f32 |
- **
sync**:Warp 内所有 32 个线程同步参与,每个线程持有 Fragment 的一部分(通过固定的线程-数据映射)。 - **
m16n8k16**:矩阵分块大小为 M=16, N=8, K=16。 - **
row.col**:A 矩阵行主序,B 矩阵列主序。
在 CUDA C++ 中,通常通过 WMMA API(nvcuda::wmma)或 CUTLASS 封装来使用 Tensor Core,而不直接编写 PTX:
1 | #include <mma.h> |
3.6.3 各架构 MMA 演进
| 架构 | 指令 | 主要改进 |
|---|---|---|
| Volta (V100) | wmma (CUDA) / mma.sync (PTX) |
首次引入 Tensor Core,支持 FP16 |
| Turing (T4) | mma.sync |
增加 INT8、INT4 支持 |
| Ampere (A100) | mma.sync (m16n8k16) |
支持 BF16、TF32,稀疏矩阵加速(2:4 sparsity) |
| Hopper (H100) | wgmma.mma_async |
Warp Group MMA(128线程),与 TMA 深度配合,支持 FP8 |
3.6.4 线程-数据映射(Thread-Data Mapping)
MMA 指令的关键难点在于理解每个线程负责 Fragment 的哪些元素。以 m16n8k16 FP16 为例:
- 一个 Warp(32 线程)共同持有 A 矩阵(16×16 FP16)的片段。
- 每个线程持有 A 矩阵中 8 个 FP16 值,分布在矩阵的特定行列位置(由 NVIDIA 官方文档给出固定映射表)。
这种映射决定了数据必须按特定方式存放在寄存器中,也是为什么从共享内存 load_matrix_sync 时对内存布局有严格要求(需消除 Bank Conflict,或使用 TMA Swizzle)。
Nvidia Tensor Core-MMA PTX编程入门 - 知乎
3.7 寄存器分配影响
寄存器(Register)是 GPU 上最快的存储单元,但每个 SM(Streaming Multiprocessor)的寄存器总量是有限的(通常为 65536 个 32-bit 寄存器)。寄存器分配策略对内核性能有两方面深远影响:Occupancy(占用率)和寄存器溢出(Register Spilling)。
3.7.1 寄存器与 Occupancy 的关系
Occupancy 是指一个 SM 上实际同时运行的 Warp 数量与 SM 理论最大 Warp 数量的比值,是衡量 GPU 利用率的重要指标。
一个 SM 的可用寄存器总数(如 65536)被所有并发 ThreadBlock 共享。每个内核的每个线程使用的寄存器越多,一个 SM 能同时容纳的 ThreadBlock / Warp 就越少,Occupancy 越低。
示例计算(以 A100 为例,SM 有 65536 寄存器,最大 64 Warp):
| 每线程寄存器数 | 每线程块(256线程)总寄存器 | 可并发线程块数 | 总并发 Warp 数 | Occupancy |
|---|---|---|---|---|
| 32 | 8192 | 8 | 64 | 100% |
| 64 | 16384 | 4 | 32 | 50% |
| 128 | 32768 | 2 | 16 | 25% |
| 255 | 65280 | 1 | 8 | 12.5% |
可以用
nvcc --ptxas-options=-v查看内核实际使用的寄存器数量。
3.7.2 控制寄存器使用量的方法
1. 编译器指令 __launch_bounds__
1 | // 告知编译器:每个 Block 最多 256 线程,每个 SM 至少运行 4 个 Block |
这会提示 NVCC 限制寄存器使用量,以满足 Occupancy 目标。代价是编译器可能无法做某些激进的寄存器优化,性能未必更好。
2. 编译器参数 --maxrregcount
1 | nvcc --maxrregcount=64 my_kernel.cu -o my_kernel |
强制限制每个线程最多使用 64 个寄存器。
3. 手动减少寄存器使用
- 减少局部变量,复用变量。
- 使用共享内存缓存中间结果(但增加延迟)。
- 将不常用的数据放入共享内存或全局内存。
3.7.3 寄存器溢出(Register Spilling)
当编译器限制了寄存器数量,但内核实际需要更多时,多余的数据会被”溢出”到 Local Memory(实际上是 L1/L2 Cache 或全局内存)。
1 | # ptxas 输出示例(表示发生了溢出) |
Register Spilling 的性能代价:
- Local Memory 访问延迟远高于寄存器(几百个时钟周期 vs. 1 个时钟周期)。
- 溢出会引发大量的 L1/L2 Cache 访问,甚至全局内存访问,严重降低计算密集型内核的性能。
3.7.4 Occupancy 与性能的关系
需要注意的是,高 Occupancy 并不总是等于高性能。这是一个常见误区:
- 高 Occupancy 的作用:主要是通过多 Warp 掩盖内存访问延迟(Latency Hiding)。对于内存带宽受限的内核,高 Occupancy 通常有益。
- 低 Occupancy 的场景:对于计算密集型内核(如使用大量 Tensor Core 的 GEMM 内核),每个 Warp 本身就能让硬件保持满负荷运行,此时低 Occupancy + 更多寄存器(减少 spilling)反而性能更好。
实际调优建议:
- 用
ncu(Nsight Compute)分析内核瓶颈,确认是计算受限(Compute Bound)还是内存受限(Memory Bound)。 - 如果内存受限,提高 Occupancy(减少寄存器用量)可能有帮助。
- 如果计算受限,不要为了提高 Occupancy 而牺牲寄存器,避免引入 spilling。
- 关注
ncu报告中的Theoretical Occupancy、Achieved Occupancy和Register File Theoretical Occupancy。
3.8 NsightCompute查看瓶颈
3.8.1 Step 0:先确认编译期寄存器数
Makefile 里 gemmV2.o 已带 -Xptxas -v,每次 make 时直接打印:
1 | ptxas info : Compiling entry function 'vector_add_dream_tma_pipelined' ... |
用这个数字做基准:
H100 每 SM 65536 个寄存器
blockDim.x = 256 时:
floor(65536 / (N_regs × 256))= 理论最大并发 block 数/SM
| N_regs | 最大 block/SM | 理论 warp occupancy |
|---|---|---|
| 64 | 4 | 1024/2048 = 50% |
| 96 | 2 | 512/2048 = 25% |
| 128 | 2 | 512/2048 = 25% |
| 256 | 1 | 256/2048 = 12.5% |
加了 __launch_bounds__(256, 2) 后,编译器会把寄存器压到 ≤128。
3.8.2 Step 1:最小化 ncu 命令——只看寄存器数和 occupancy
1 | cd /home/ethereal/vm2/dream/uvm/jwsz_dream/benchmarks/seq |
输出解读:
| Metric | 含义 | 判断 |
|---|---|---|
launch__registers_per_thread |
每线程实际用的寄存器数 | 对照 Step 0 的计算 |
sm__maximum_warps_per_active_cycle_pct |
理论 occupancy(寄存器/smem/blockDim 三者取最小) | 看上限在哪 |
sm__warps_active.avg.pct_of_peak_sustained_active |
实测 occupancy(warp 真正活跃的比例) | 看实际执行情况 |
典型场景解读:
1 | 理论 occupancy = 25%,实测 occupancy = 24% |
1 | 理论 occupancy = 50%,实测 occupancy = 15% |
3.8.3 Step 2:确认 smem 也不是限制因素
smem 同样限制 occupancy,需要排除:
1 | ncu --metrics "launch__shared_mem_per_block_static,launch__shared_mem_per_block_dynamic,sm__maximum_warps_per_active_cycle_pct" \ |
smem_bytes = request_size × sizeof(float) = 2048 × 4 = 8192 bytes = 8 KB
H100 每 SM 228 KB smem;以 8 KB/block 计,最多 floor(228/8) = 28 个 block/SM,smem 不是瓶颈。
3.8.4 Step 3:判断瓶颈是计算、内存还是延迟
1 | ncu --metrics "smsp__inst_executed.avg.pct_of_peak_sustained_elapsed,smsp__sass_average_data_bytes_per_sector_mem_global_op_ld.pct,l1tex__t_sector_hit_rate.pct,smsp__warp_issue_stalled_long_scoreboard_per_warp_active.pct" \ |
| Metric | 高 → 瓶颈 |
|---|---|
smsp__inst_executed.avg.pct_of_peak_sustained_elapsed |
高 → 计算密集(compute bound) |
smsp__inst_executed.avg.pct_of_peak_sustained_elapsed |
高 → 计算密集(compute bound) |
smsp__warp_issue_stalled_long_scoreboard_per_warp_active.pct |
高 → 等内存返回(memory latency bound) |
l1tex__t_sector_hit_rate.pct |
低 → L1 cache 命中率差,需要更多 warp 来隐藏延迟 |
smsp__sass_average_data_bytes_per_sector_mem_global_op_ld.pct |
低 → 内存访问效率差(可能是随机访问) |
如果 long_scoreboard stall 很高:
说明 warp 在等内存,增加 occupancy(减寄存器)可以用更多 warp 覆盖这个延迟
这时减寄存器有意义
3.8.5 Step 4:一键生成完整报告(Roofline)
1 | ncu --set full \ |
在本机 Nsight Compute GUI 里打开 gemmV2_register_profile.ncu-rep,在 Roofline 页面可以直接看 kernel 落在哪条屋顶线下方(compute roof 还是 memory bandwidth roof)。
如何阅读?
图中的蓝线代表了当前硬件的物理极限:
水平实线(平屋顶) - 算力瓶颈 (Compute Bound):
这条横线代表了硬件的理论峰值计算性能(在这张图上大约在 20-30 TFLOP/s 之间)。
无论你的算法有多完美,单精度浮点运算的速度都不可能超过这条线。
斜线(斜屋顶) - 内存/带宽瓶颈 (Memory Bound):
图中有三条斜线,它们通常代表不同层级的内存带宽(例如:L1缓存、L2缓存、主内存DRAM)。最左侧的斜线代表最慢的内存(主存),最右侧的斜线代表最快的缓存。
斜线的斜率就是该层级内存的峰值带宽。如果你的算术强度(X轴)很低,性能就会被卡在这些斜线下方,因为计算单元得不到足够的数据喂养。
转折点 (Ridge Point):
- 斜线和水平线的交点。它表示为了达到硬件的最高计算性能,你的程序至少需要达到多大的算术强度。
图中的彩色圆点代表你实际测试的不同程序、函数或Kernel:
如果圆点贴近斜线(如左侧的紫色和橙色点):
诊断:你的程序处于内存受限(Memory Bound)状态。此时程序的算术强度低(约 $0.5$),主要瓶颈是内存传输速度太慢,计算核心在“干等”数据。
优化方向:优化内存访问模式、合并访存、使用缓存分块(Cache Blocking)等减少内存读取的操作。
如果圆点在右侧很远,但离水平线很远(如右侧的绿色点):
诊断:这个点的算术强度很高(接近 $300$),按理说不缺数据,但性能只有 $1$ TFLOP/s,远低于硬件峰值(平屋顶)。这说明它既没有被内存卡住,也没有发挥出计算性能。
优化方向:可能是代码没有很好地向量化(Vectorization)、存在严重的指令依赖、分支预测失败、或者线程负载不均衡。需要针对指令级或线程级进行计算优化。
如果圆点贴近水平线:
- 诊断:恭喜你,你的程序处于计算受限(Compute Bound),并且已经榨干了硬件的算力,优化空间已经很小了。
3.8.6 Step 5:对比 __launch_bounds__ 前后效果
先备份:
1 | cp gemmV2.cu gemmV2_baseline.cu |
编译两个版本分别 profile:
1 | # 修改前(注释掉 __launch_bounds__) |
若改后 sm__warps_active 明显上升 → 减寄存器有效,occupancy 提高了。
若基本不变 → 瓶颈不在寄存器,看 Step 3 的 stall 原因。
3.8.7 快速决策树
1 | ncu 跑完后: |
3.8.8 注意事项
ncuprofiling 会显著拖慢 kernel 执行,建议--iters 1DREAM 的 RDMA 路径可能导致 ncu 等待超时,加
--launch-timeout 120000(毫秒)若 kernel 跑不起来(RDMA 初始化失败),先用
--mode uvm验证 ncu 环境
参考
(15 封私信 / 80 条消息) 新兴 Python 算子开发:Triton、CuTeDSL、MOJO 🔥等概览 - 知乎
(15 封私信 / 80 条消息) OpenAI Triton 入门教程 - 知乎
(15 封私信 / 80 条消息) Ubuntu 20.04 下安装运行 GPGPU-Sim - 知乎
accel-sim/accel-sim-framework: This is the top-level repository for the Accel-Sim framework.
玩转 gpgpu-sim 01记 —— try it-CSDN博客
a1245967/gpgpusim - Docker Image | Docker Hub
accel-sim/accel-sim-framework: This is the top-level repository for the Accel-Sim framework.
accel-sim/accel-sim-framework: This is the top-level repository for the Accel-Sim framework.
(15 封私信 / 80 条消息) CuTeDSL(CUTLASS Python)的初步实践 - 知乎
实用指南:第0记 cutlass 介绍及入门编程使用 - yfceshi - 博客园
(15 封私信 / 80 条消息) CUTLASS 基础介绍 - 知乎
(15 封私信 / 80 条消息) 一文读懂CUDA常用库: CUBLAS、CUDNN、CUTLASS - 知乎
CUDA Toolkit 11.0 Download | NVIDIA Developer
CUDA Toolkit Archive | NVIDIA Developer
CUDA Toolkit 12.4 Update 1 Downloads | NVIDIA 开发者
- Title: gpu learning
- Author: Ethereal
- Created at: 2025-10-25 16:00:21
- Updated at: 2026-05-08 18:41:14
- Link: https://ethereal-o.github.io/2025/10/25/gpu-learning/
- License: This work is licensed under CC BY-NC-SA 4.0.